
1
Create a database
- Sign up for an invite to Nile if you don’t have one already
- You should see a welcome message. Click on “Lets get started”
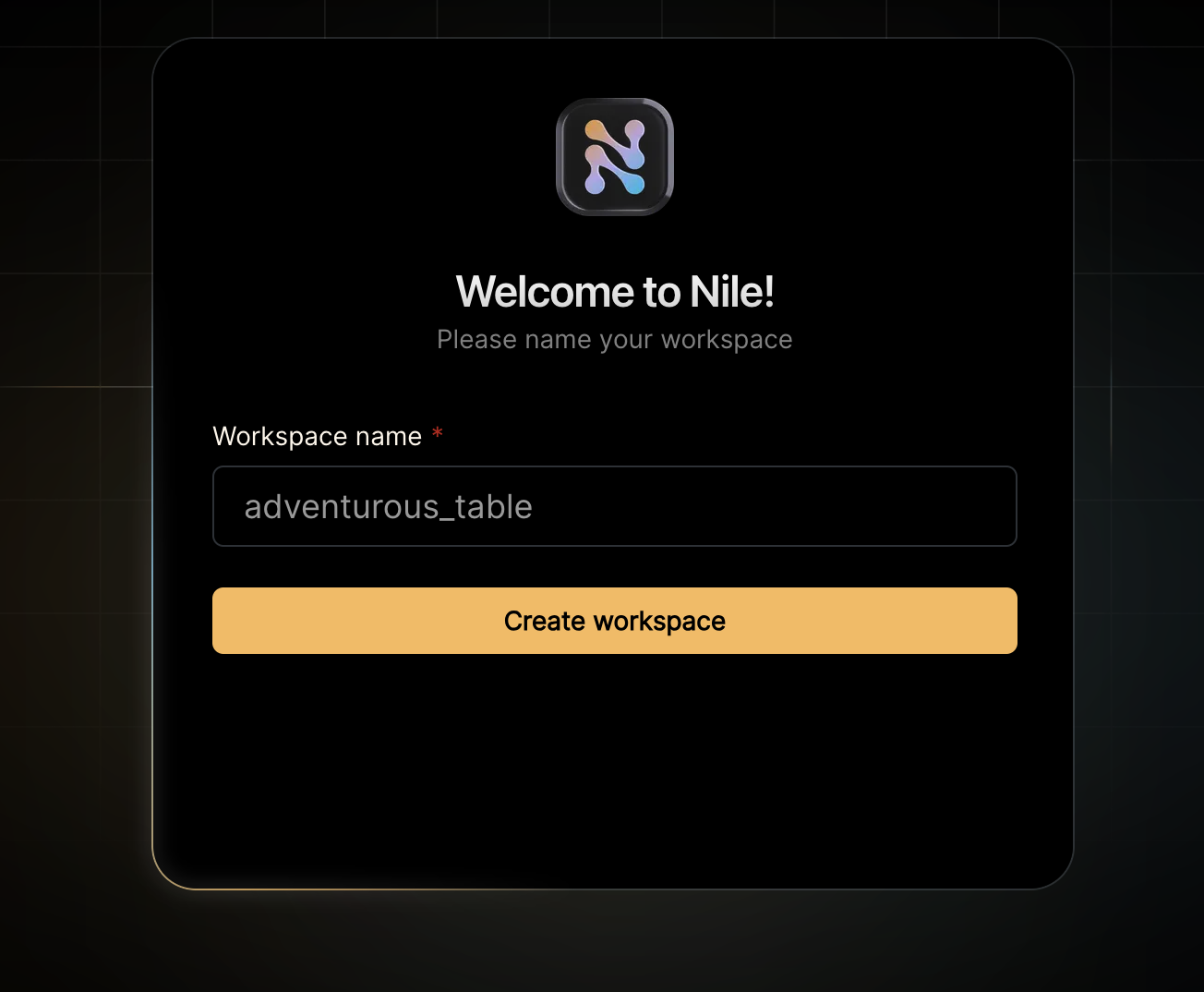
- Give your workspace and database names, or you can accept the default auto-generated names. In order to complete this quickstart in a browser, make sure you select to “Use Token in Browser”.
2
Create a table
After you created a database, you will land in Nile’s query editor. Since our application requires a table for storing all the “todos” this is a good time to create one:You will see the new table in the panel on the left side of the screen, and you can expand it to view the columns.The embedding column is a vector representation of the task. When the user adds new tasks, we will use these embeddings to find
semantically related tasks and use this as a basis of our AI-driven time estimates. This technique - looking up related data using embeddings and
using this data with text generation models is a key part of RAG (Retrieval Augumented Generation).See the 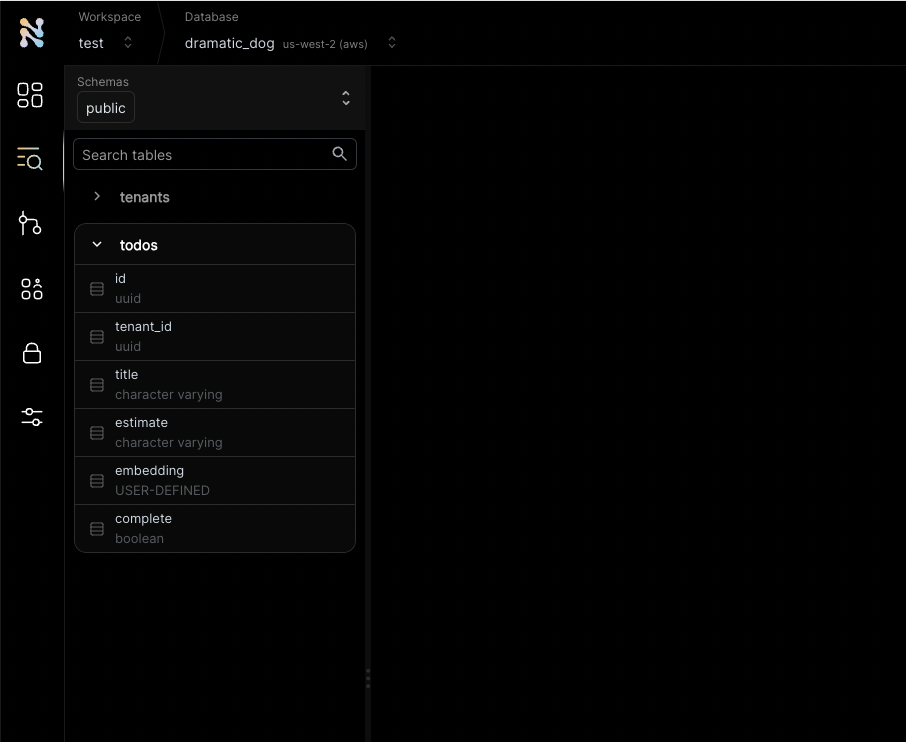
tenant_id column? By specifying this column, You are making the table tenant aware. The rows in it will belong to specific tenants. If you leave it out, the table is considered shared, more on this later.3
Get credentials
In the left-hand menu, click on “Settings” and then select “Connection”.Click on the Postgres button, then click “Generate Credentials” on the top right corner. Copy the connection string - it should now contain the credentials we just generated.
4
Get third party credentials
This example uses AI chat and embedding models to generate automated time estimates for each task in the todo
list. In order to use this functionality, you will need access to models from a vendor with OpenAI compatible
APIs. Make sure you have an API key, API base URL and the names of the models you’ll want to use.
5
Set the environment
Enough GUI for now. Let’s get to some code.If you haven’t cloned this repository yet, now will be an excellent time to do so.Rename Install dependencies with
.env.example to .env, and update it with the connection string you just
copied from Nile Console and the configuration of your AI vendor and model. Make sure you don’t include
the word “psql”. It should look something like this:yarn install or npm install.6
Run the application
Start the web service with
npm start or yarn start.
Now you can use curl to explore the APIs. Here are a few examples:7
Check the data in Nile
Go back to the Nile query editor and see the data you created from the app.You should see all the todos you created, and the tenants they belong to.If you create more tasks via the REST APIs, the estimates for new tasks will use the embeddings of the existing tasks to
generate the estimates.
8
What's next?
This example is a good starting point for building your own application with Nile.You have learned basic Nile, AI and RAG concepts and how to use them with Drizzle ORM.You can learn how the example application works more in detail below or you can learn
more about Nile’s tenant virtualization features in the following tutorials:You can explore Nile’s JS SDK in the SDK reference.You can learn More about AI in Nile, or try a more advanced example like:
How does it work?
Let’s take a look at the code. The web application starting point is insrc/app.ts.
It creates an Express app, and sets up some of the usual middleware:
tenantDB which wraps Drizzle and passes the tenant context to Nile.
And of course, the handler that uses AI models to automatically estimate the time to complete tasks.
Lets look at these one by one.
Tenant Context Middleware
Immediately after the middleware that sets up the Express app, we add a middleware that introduces Nile’s tenant context to the application:AsyncLocalStorage - which provides a way to store data that is global and unique per execution context.
The data we are storing is the tenant ID, and by passing next as the second argument to tenantContext.run we are making sure that all the code that runs after this middleware will have access to the tenant ID.
TenantDB
Now lets take a look atdb/db.ts - this is where we set up Drizzle and connect it to Nile. We use pg client as the driver for Drizzle, and we pass it the connection string from the environment.
tenantDB function. This is where we wrap Drizzle with Nile’s tenant virtualization features.
We need Drizzle to set Nile context on the connection before each query we execute. We do this by accepting each query as a callback and wrapping it in a transaction that starts with set nile.tenant_id.
We get the tenant ID from the tenant context, which we set earlier in the middleware.
Tying it all together - handling a request for all todos for a tenant
Now that we understand how the tenant context andtenantDB work, lets take a look at how we use them to handle a request for all todos for a tenant.
We are using the tenantDB function to execute a query that returns all the todos for a tenant.
The query doesn’t need to include the tenant ID in the where clause, because tenantDB will set it in the context.
Using AI models to estimate time to complete tasks
This example uses AI chat and embedding models to generate automated time estimates for each task in the todo list. We handle the time estimates in the route handler forapp.post("/api/tenants/:tenantId/todos". This handler executes when users add new tasks.
This is what the handler code looks like:
findSimilarTasks, aiEstimate and embedTask are all defined in AiUtils.ts.
They are wrappers around standard AI model calls and database queries, and they handle the specifics of the AI model we are using.
This will make it easy to switch models in the future.
Getting similar tasks is done by querying the database for tasks with similar embeddings.
SEARCH_QUERY task type. This is because we are looking for
similar tasks to the new task. We use an embedding model from the nomic family, which is trained to perform specific types of embedding tasks. Telling it that we are generating the embedding for a lookup vs
generating an embedding that we will store with the document (as we’ll do in a bit), should help the model produce more relevant results.
DrizzleORM provides the magical sql method, as well as the cosineDistance function, which we use to work
with pg_vector and calculate the similarity between the embeddings of the new task and the existing tasks.
As you can see, we filter out results where the cosine distance is higher than 1.
The lower the cosine distance is, the more similar the tasks are (0 indicate that they are identical).
A cosine distance of 1 means that the vectors are essentially unrelated, and when cosine distance is closer to 2, it indicates that the vectors are semantically opposites.
The embedTask function uses the embedding model to generate the embedding and is a very simple wrapper on the model:
aiEstimate to generate the time estimate.
This function also wraps a model, this time a conversation model rather than an embedding model. And it icludes the similar tasks in the promopt, so the model will
generate similar estimates:
But wait, what’s todoSchema and tenantSchema?
You may have noticed that we are not using the table name directly in the code. Instead, we are usingtodoSchema and tenantSchema.
We defined these in src/db/schema.ts, and these are the objects that Drizzle uses to interact with the database. It is an object that maps to the tables in our database.
Drizzle can also generate migration files from these objects, and we can use them to create the tables in the database.