
When building a new application, there is a lot to be said for building it completely serverless: You can focus on the code instead of tinkering with deployments and configuration. Because you don't need to worry about deployment at this point, you can actually ship a better long-term architecture with multiple services and clear APIs between them. And best of all - until you actually get users for your application, you barely pay anything.
Nile provides Serverless Postgres database with tenant-awareness, so you can provision Postgres in a click and start building your B2B application. Now it is time to choose serverless compute. If you are using Python, and there's a good chance that you are, then Modal is going to be a great fit for you.
Modal is a serverless compute platform that lets developers deploy Python apps (anything from web services, data processing, Slack bots…) to the cloud by adding few annotations to perfectly normal Python code. To make things even sweeter - they have a nice collection of GPUs that can be used to run LLMs and make these applications smart.
In this blog, I'm going to explain how I built Serverless Sales Insights application with Nile, Modal and running my own Llama 3.1 model. This is what the application looks like:
I'll start by introducing the architecture I went with, explain some key design decisions, and then demonstrate how easy it is to use Modal and Nile together with some code snippets. You can find all the code for the app including deployment instructions here, and you can try it for yourself here.
Architecture
We went with fairly standard RAG architecture, but as you can see below, we split it into 3 distinct parts:
- Ingest and embedding pipeline for processing recordings of sales calls and storing the chunks and embeddings in the database. This can happen continuously offline.
- Web application where the user can browse calls and ask for things like key customer needs and next steps. The web application uses vector search to find relevant chunks of conversation and sends them to the LLM.
- LLM service is the brains of the operation. It takes the question and relevant chunks, applies a built-in prompt and its training and generates a response.
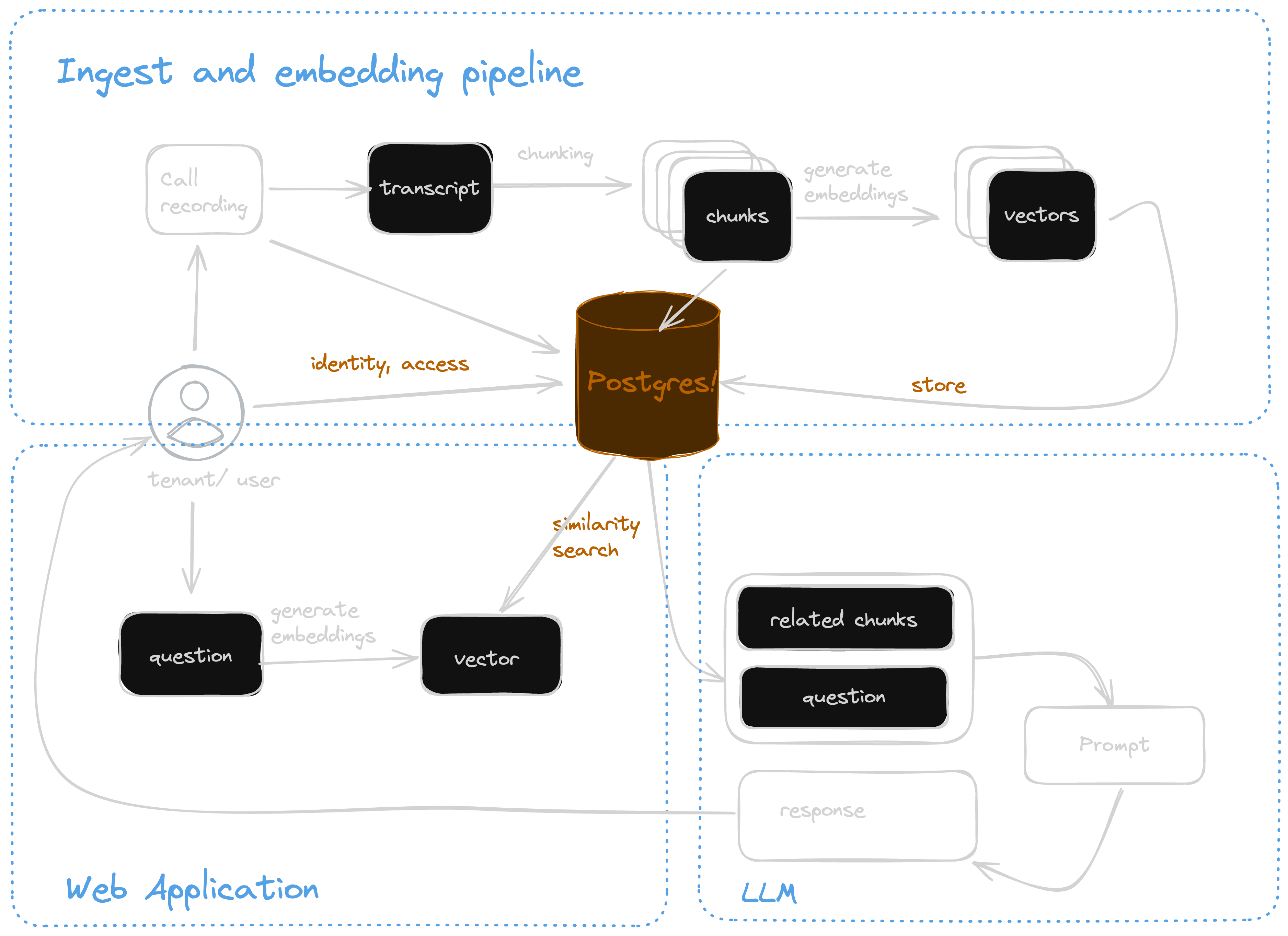
Using Modal, we can easily deploy each part as its own service. Modal doesn't just handle the deployment, it also handles the communication between services. As you'll see below, the call from the web app to the LLM looks like I'm calling a method in the LLM class. From my perspective, this is exactly what I'm doing. Somewhere behind the scenes, Modal turns this into a gRPC call and handles all the details around this. If you've ever had to do it yourself using Python's Pickle, you can appreciate the convenience of Modal.
Obviously, we are using Nile as our database. After signing up for Nile, you can create a database in a click, generate a connection string with credentials, and store it as a Modal secret (The README has step-by-step instructions on how to do this). Once you have the connection string in Modal secret, Modal can automatically inject it into your app as an environment variable.
Perhaps the most controversial choice I've made here was to deploy the LLM to Modal rather than use some LLM-as-a-service provider like OpenAI. Model vendors are really great - they make it super quick and easy to use the models they provide. But, as you can see below, HuggingFace has almost a million models. And more are added literally every minute.
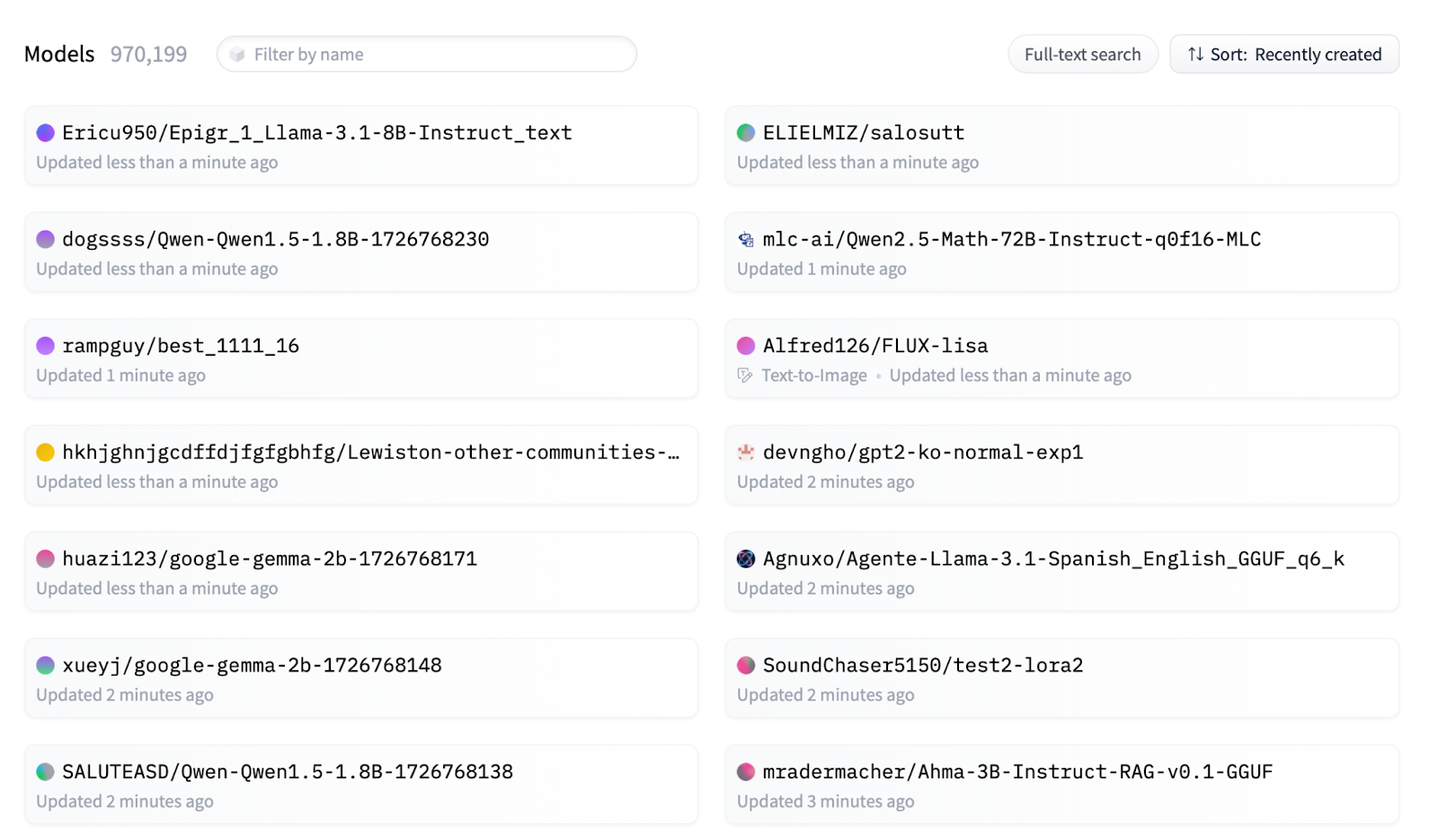
Only a tiny fraction is offered by the main vendors. If you are like me and enjoy exploring, not just new models, but also variations like fine-tuning and quantization of popular models - you really want to familiarize yourself with running a model. Even if you are perfectly happy working with a vendor, it can be a great learning experience to run a model yourself at least once.
Implementation Highlights
Enough with the fluff! Lets take a look at how we built all this. The entire example code is small and most of it is standard web application things. So I'll guide you through the interesting bits.
Serving backend and frontend from Modal
We wrote our backend with FastAPI, which is simple to deploy with Modal, but we had two additional requirements.
The first is that I wanted to serve the frontend from the same webapp that has the backend APIs. The app frontend is essentially single page app (SPA) in React. We packaged it into static files using Vite. FastAPI can serve static assets. So we just needed to upload the files to a mounted volume and point FastAPI to it.
In many serverless compute platforms this would be straight out impossible. You can't attach a disk to a function. You basically have to deploy your frontend and backend separately, or use a serverless platform that specializes in serving web UI and match your backend to the way they serve functions. Modal lets me just create a disk and upload files. The webapp itself can keep running as is.
The second requirement is that, like every good Pythonista, I had a whole list of modules that I wanted to use. And even for modules that are part of Modal's default lightweight image, I had specific versions that I wanted to use.
Here's what implementing both of these looks like with Modal:
web_ui_dir = "./ui/dist"
# place all static images in root of mount
mount = modal.Mount.from_local_dir(web_ui_dir, remote_path="/")
# Install dependencies and copy web ui assets into the image
image = modal.Image.debian_slim(python_version="3.10").pip_install(
"passlib==1.7.4",
"python-jose==3.3.0",
"sqlmodel==0.0.21",
"pgvector==0.3.2",
"pydantic==2.8.2",
"fastapi==0.112.2",
"python-dotenv==1.0.1",
"psycopg2-binary==2.9.9",
"sqlalchemy==2.0.32",
"openai==1.42.0"
).copy_mount(mount, remote_path="/root/ui/dist")
app = modal.App(name=app_name+"-web", image=image)
I also need to let Modal know that we also have an LLM module as part of this application. This is easy:
from llm_app import llm_app, Model
app.include(llm_app)
I just import the module and tell the Modal app to include it. And finally, lets tell Modal to serve my FastAPI app:
# Modal function that returns the FastAPI app object, this is the entrypoint for the webapp
@app.function(secrets=[
modal.Secret.from_name("database_url"),
modal.Secret.from_name("embedding-config")])
@modal.asgi_app()
def fastapi_app():
return web_app
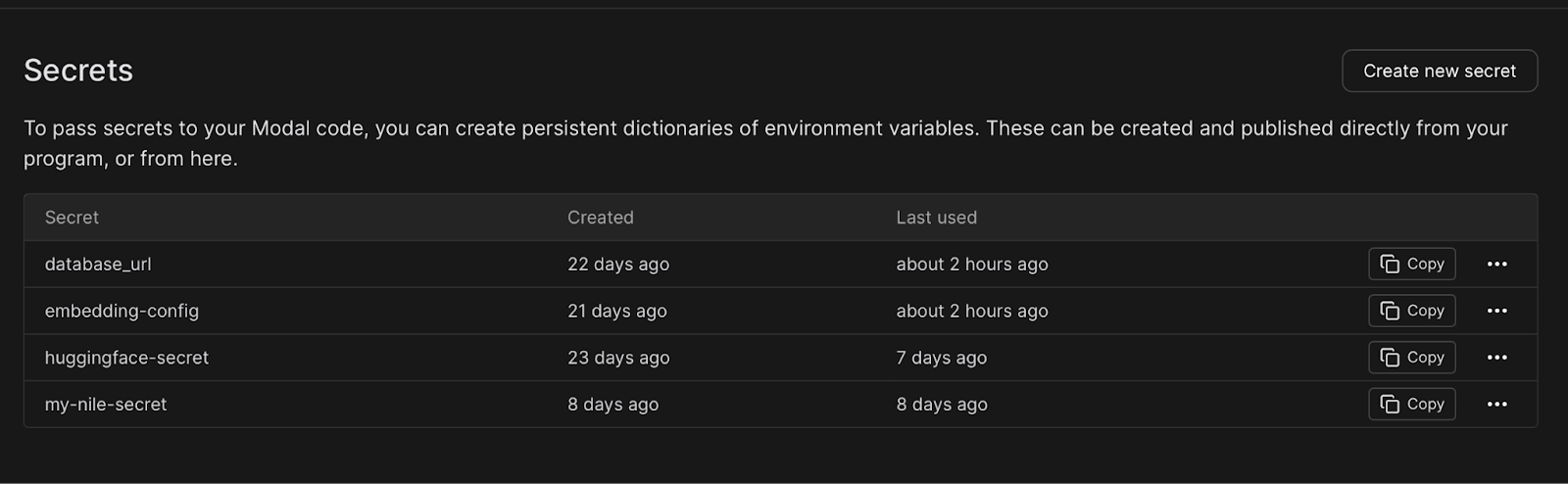
You can see here that when telling Modal to create an entry point here, I also ask it to load two secrets. The first is the connection string to Nile, which contains my database password. You create these secrets in Modal, and once the secrets are loaded, they are available to the application as environment variables.
Working with Nile's virtual tenant databases
We use SQLAlchemy as the ORM and SQL Model to integrate it with FastAPI. This allowed us to use the same data model definitions both to handle REST requests and responses, and to persist the data in the database. In order to connect SQLAlchemy to our database, we used the environment variable that was created from a Modal secret. After creating the database in Nile, we generated a connection string with credentials, and stored it as a Modal secret (The README has step-by-step instructions on how to do this).
As you've seen above, when we defined the webapp as a Modal function, we asked Modal to load the DATABASE_URL secret for us. This secret is automatically available as an environment variable.
engine = create_engine(
os.getenv("DATABASE_URL"),
echo=log_sql)
Because Nile is a tenant aware database, which allows you to work specifically with virtual databases of specific tenants, we created two types of database sessions - a global session, which is used when no tenant is defined (before creating a tenant) and a tenant session that applies every query to just a specific tenant:
# use this for cases where you don't want a specific tenant database,
# when creating a new tenant or signing up new users
def get_global_session():
session = Session(bind=engine)
yield session
# This is a session for a specific tenant DB.
# If there is no valid tenant_id in the context, it will throw an exception
# (InvalidTextRepresentation) and the request will fail.
def get_tenant_session():
session = Session(bind=engine)
try:
tenant_id = get_tenant_id()
user_id = get_user_id()
session.execute(text(f"SET LOCAL nile.tenant_id='{tenant_id}';"))
# This will raise an error if user_id doesn't exist or doesn't have access to the tenant DB.
session.execute(text(f"SET LOCAL nile.user_id='{user_id}';"))
yield session
except:
session.rollback()
raise
finally: # This will run after the request handler is finished with the session
session.commit()
pass
We also use a middleware function to grab the tenant identifier from the requests, so it is available get_tenant_session() function.
Once the middleware and sessions are set, using the DB is almost transparent.
This is an example of a REST API that lists all conversations for a tenant:
@web_app.get("/api/conversations")
async def list_conversations(request: Request, session = Depends(get_tenant_session)):
logger.debug(f"Tenant ID: {get_tenant_id()}")
# Query distinct conversation_id values from the Chunk table, ordered alphabetically
distinct_conversations = session\
.query(distinct(Chunk.conversation_id))\
.order_by(Chunk.conversation_id).all()
# Extract the conversation_id values from the result
conversation_ids = [conv[0] for conv in distinct_conversations]
return conversation_ids
Because we have the tenant-aware session that connects to the tenant DB, we didn't need to filter the conversations by tenant. Getting all conversations will only return the ones that belong to the tenant.
Finding Relevant Conversation Chunks
Finding relevant context to provide to the LLM is key for any RAG application. If you manage to find relevant information - the LLM will be able to provide a great response.
Typically, you use an embedding model to generate an embedding from the customer question. Then use vector distance function to find the closest documents in the database that match the question and pull these as context.
However, during early experiments with the Sales Insights application, we discovered that just naively doing this is not enough. If the question was “what were the customer pain points”, we are very likely to find chunks where the sales person ask the customer about their challenges or what they don't like about the existing solution. But the customer response doesn't always show as similar.
We solved it by pulling not just the chunks that are near-by based on vector distance, but also the chunks immediately preceding and succeeding in the conversation (and then removing duplicates). This is a very common Graph RAG technique. But you don't need a graph database to do this!
def get_similar_chunks(session: any, embedding: List[float], conversation_id: int):
query = """
with src as (
SELECT * FROM call_chunks
WHERE conversation_id = '{}'
AND (embedding <=> '{}') < 1
ORDER BY embedding <=> '{}' LIMIT 3 )
select distinct on (cc.chunk_id) cc.chunk_id, cc.conversation_id, cc.speaker_role, cc.content
from src join call_chunks as cc on
cc.conversation_id = src.conversation_id
and cc.tenant_id = src.tenant_id
and cc.chunk_id >= src.chunk_id -1
and cc.chunk_id <= src.chunk_id + 1;
""".format(conversation_id, embedding, embedding)
similar_chunks_raw = session.execute(text(query))
return [{"conversation_id": chunk.conversation_id,
"speaker_role": chunk.speaker_role,
"content": chunk.content} for chunk in similar_chunks_raw]
Using and deploying the LLM
Using the LLM is almost embarrassingly simple. It is literally just a function call with the prompt, the customer question and the context we just retrieved:
model.generate_stream.remote_gen(
system_prompt="You are a helpful assistant that can summarize sales calls for "
"busy sales people. The user will ask a question, and you will use the provided "
"conversation transcript to answer the question. ",
user_query="Please answer the question based on the provided conversation transcript. "
"Respond with a concise answer and include relevant quotes "
"from the conversation transcript. Don't include any other text. "
"Conversation transcript: " + str(similar_chunks) + " Question: " + chat_data.question,
max_tokens=200,
frequency_penalty=0.6,
presence_penalty=0.6,
)
But how do we deploy the LLM?
We used a framework called vLLM that can be used to deploy a wide range of models. There are two ways to use it - via HTTP API compatible with OpenAI, or by calling generate directly. We opted for the latter.
Before deploying anything, you need to download the model and weights to a volume (just like we did for the UI assets earlier). Instead of downloading the weights to local disk and then uploading them to modal, it is much faster to run a small function on Modal that downloads the weights to an attached volume. Later we’ll attach this volume to the LLM image.
In order to use vLLM, we install it on an image and mount the volume with the model weights:
vllm_image = modal.Image.debian_slim(python_version="3.10").pip_install(
"vllm==0.5.5"
)
try:
volume = modal.Volume.lookup(MODELS_VOLUME, create_if_missing=False)
except modal.exception.NotFoundError:
raise Exception(""" Download models first with "modal run download_llama.py" """)
And then ask Modal to run this module on a GPU:
GPU_CONFIG = modal.gpu.A100(count=1, size="40GB")
@llm_app.cls(gpu=GPU_CONFIG, volumes={MODELS_DIR: volume},
secrets=[modal.Secret.from_name("huggingface-secret")], allow_concurrent_inputs=10)
The machine is beefy enough to serve multiple inference requests at once, so we let it. In order to minimize latency involved in spinning up the LLM, we used 4 techniques:
- Download the model and weights in advance
- Load the model in a function decorated by @modal.enter() - so it will be reused between function calls.
- Introduce a method called wake_up() that does nothing, but can be called earlier in the application, before the user actually asks anything. This allows us to hide the latency of the first time the model loads.
- Use a nicely optimized model and the right GPU for it, based on recommendations by the awesome team at Modal.
And thats it! We are running our own Llama 3.1 model on Modal, and can use it to answer questions about our sales calls based on the embeddings we have in Nile.
Summary
Building a fully serverless application makes it easy to focus on building the right architecture while not worrying about the details of deploying it. In this blog, we explore how combining Nile's tenant-aware PostgreSQL and Modal's serverless compute platform can make your B2B applications trivial to build, deploy and scale. Additionally, the flexibility to deploy your own models, like Llama 3.1, adds a layer of customization that typical LLM services can't provide.
Ready to streamline your application development process with serverless architecture? Try the Sales Insights app yourself and see how easy it is to build with Nile and Modal!
Last, but not least, I owe huge thanks to Charles Frye from Modal for his patient review and very helpful suggestions around choice of model, reducing latency and many other improvements.