
I am excited to announce that Nile is live today! Nile is a Postgres platform that decouples storage from compute, virtualizes tenants, and supports vertical and horizontal scaling globally to ship AI-native B2B applications fast while being safe with limitless scale. Nile is in public preview, and we look forward to all the feedback as we move towards GA. Sign up to Nile and get started today! Try our quickstarts or use one of our numerous AI examples or use cases.
Nile’s goal is simple - To be the best platform to build and scale multi-tenant AI applications.
We are taking a new approach to building databases that have not been attempted before. We are virtualizing the concept of a customer (or tenant) into Postgres, making Postgres and its ecosystem perfect for creating B2B AI companies. We have been working on this for the past eighteen months, and we believe it is the fastest and safest way to develop AI-native B2B applications and scale globally.
Why B2B, Why AI, and Why Postgres?
Modern relational databases have been in existence for several decades. They have undergone numerous improvements, becoming significantly faster and capable of supporting more relational features. However, the gap between the application and the database has continued to grow. There are a significant number of problems that are being tackled by B2B developers, which should be solved within the database. A general-purpose DB will always be designed to solve only the lowest common denominator and push a lot of problems unique to B2B to the application layer.
Multi-tenant architectures - can you have the cake and eat it too?
The foundation of B2B applications is a multi-tenant architecture, where each tenant typically represents a customer, workspace, organization, etc. The main challenge is how to store and query many customers/tenants in the database. Various patterns have been proposed, but at a high level, there are two main approaches.
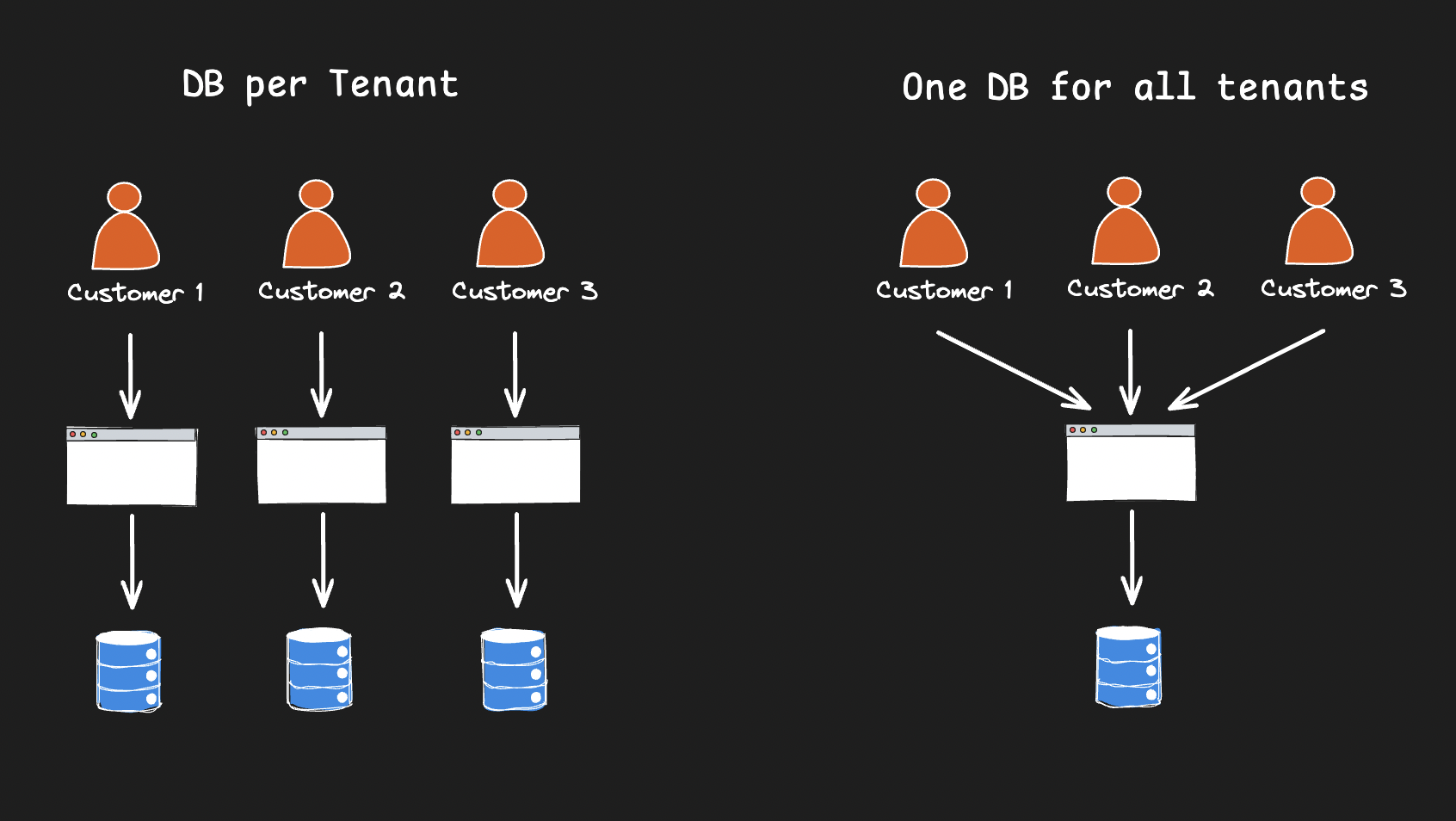 On one extreme, you can use one database per tenant. This approach has several benefits but also entails many pain points.
On one extreme, you can use one database per tenant. This approach has several benefits but also entails many pain points.
Benefits
- Full isolation across customers, making it very difficult to leak data.
- Backups, performance insights, and read replicas are all specific to each customer which is a huge advantage for low MTTR per customer.
Drawbacks
- Significant cost: each database is typically deployed into its own virtual machine and has a minimum size. While you could bring the databases down when the tenants are inactive to save costs, this does not work well due to cold start time, and many tenants have low utilization (as opposed to no utilization).
- Schema migration across tenants is difficult, especially when adding tenants in a self-serve manner. Deploying a new database and applying schema in a self-serve product becomes complex.
- No ability to query across tenants. There is always a need to build internal customer dashboards and query across tenants for analytical purposes.
- The application has to be designed to work with multiple databases, custom routing, and multiple connection pools.
- Lots of tooling is needed to do fleet upgrades, metrics aggregation, alerting, and data ingestion from back-office tools into the DB.
The other extreme is to have one database across tenants.
Benefits
- Simplicity. Application is designed to talk to one database and all the operational overhead for tenant per DB does not exist.
- Lower cost since multiple tenants are in the same DB. You pay for one DB’s provisioned capacity.
- Pretty much all the drawbacks of per DB model is a plus here
Drawbacks
- Restricting access to a tenant data is not trivial. Need to enforce complex row-level security in the DB which is hard to debug or apply authorization at the application that could easily leak.
- Noisy neighbor problems between tenants as some tenants grow to be active
- No per-tenant query insights, backups, or read replicas that are super useful to reduce MTTR
Most companies end up having to support a hybrid approach. Companies start with one of the two approaches, and grow into the other, if successful. The reason is that as companies grow they typically have to place a subset of customers in their own database or in a particular region for compliance, isolation or latency reasons. The question is can you get all the benefits of both the architecture models without any of the downsides right from the start? Would it be possible to do this 10x cheaper and with the experience of a single database?
Building RAG apps with customer data
AI is fundamentally changing how applications are built and consumed. One of the core architectural patterns for AI apps is Retrieval Augmented Generation (RAG). This approach involves:
- Calculating vector embeddings for your input dataset
- Using the user's prompt to search for relevant embeddings
- Finding the relevant documents or chunks within the documents
- Feeding these documents along with the prompt to the Large Language Model (LLM) to get the most accurate answer
RAGs are becoming a critical part of AI infrastructure. The vector embeddings computed from customer data need to be stored, queried, and scaled to millions. AI has dramatically accelerated the speed of adoption—what once took 2–3 years to reach scale is now possible in just 6 months. This explosion of AI adoption and the challenge of managing vector embeddings for RAG raise numerous problems.
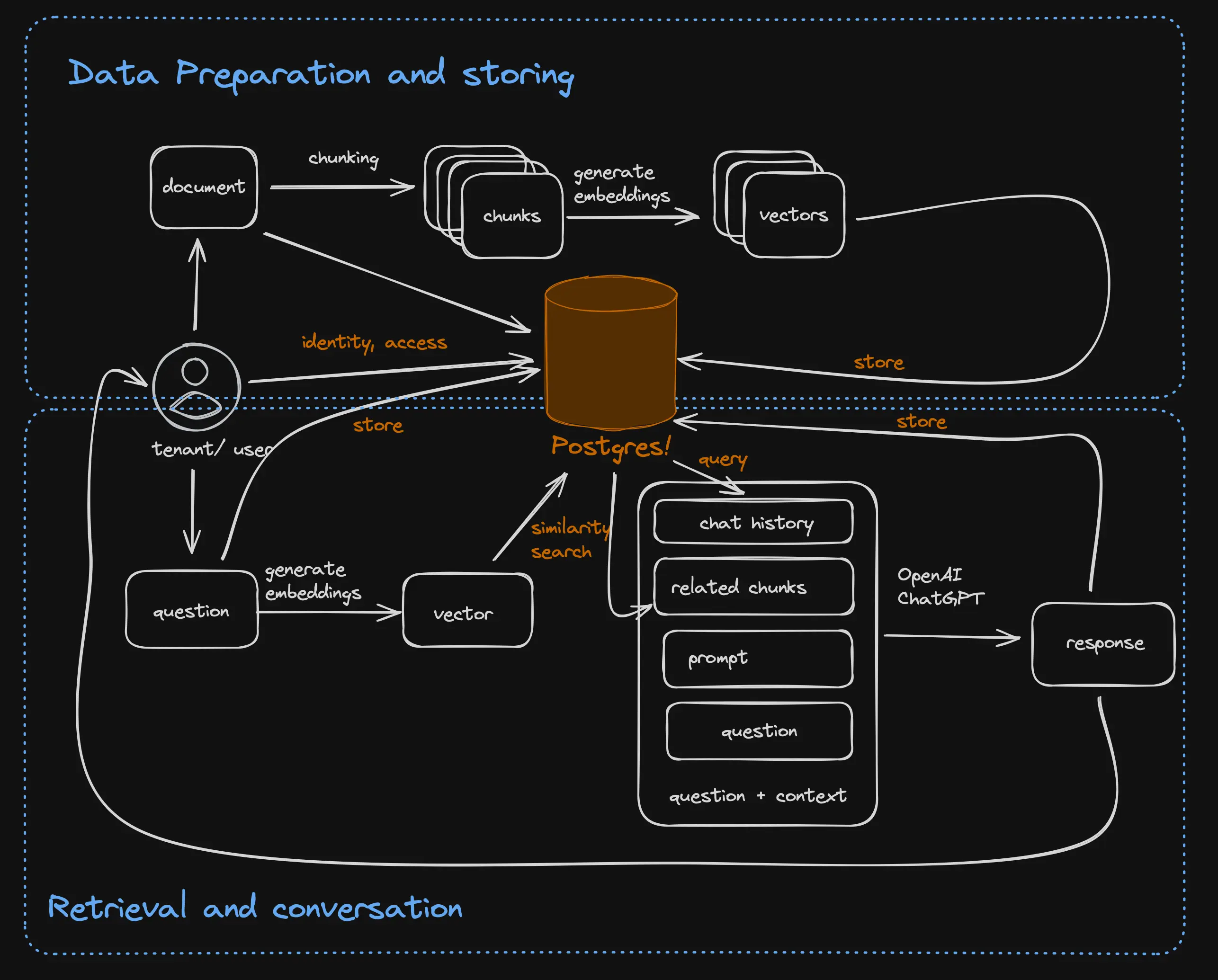
Separate databases for vector embeddings and customer data
In recent years, numerous vector databases have emerged. This trend separates customers' core data and metadata from their embeddings, forcing companies to manage multiple databases. Such separation increases costs, significantly complicates application development and operation, and leads to inefficient resource utilization between vector embeddings and customer metadata. Moreover, keeping these databases synchronized with customer changes adds yet another layer of complexity.
Lack of isolation for customer workloads
AI workloads demand significantly more memory and compute than traditional SaaS workloads. Customer adoption and growth are much faster with AI, though some of this can be attributed to a hype cycle. Moreover, rebuilding indexes for embeddings requires additional resources and may impact production workloads. The ability to isolate customer data and their AI workloads has a significant impact on the customer's experience. Isolation is a key customer requirement (no one wants their data mixed with anyone else’s) and also critical to performance - 3 million embeddings is very large. 1000 tenants with 3000 embeddings each is very manageable - you get lower latency and 100% recall.
Scaling to billions of embeddings across customers
AI workloads scale to 50-100 million embeddings and in some cases even a billion embeddings. The biggest unlock with AI is the ability to search through unstructured data. All the data in different PDFs, Images, Wikis are now searchable. In addition, these unstructured data need to be chunked to do better contextual search. The explosion of vector embeddings requires a scalable database that can store billions of embeddings at a really low cost.
Connecting all the customer’s data to the OLTP
90% of AI use cases involve extracting data from customers' various SaaS services, making it accessible to LLMs, and allowing users to write prompts against this data. For instance, Glean, an AI-first company, aggregates data from issue trackers, wikis, and Salesforce, making it searchable in one central location using LLMs. Glean must offer a streamlined process for each customer to extract data from their SaaS APIs and transfer it to Glean's database. This data needs to be stored and managed on a per-customer basis. Vector embeddings must be computed during data ingestion. In the AI era, ETL pipelines from SaaS services to OLTP databases need to be reimagined for each customer.
Cost of computing, storing and querying customer vector embeddings
The sheer scale of vector embeddings and their associated workloads significantly increases the cost of managing AI infrastructure. The primary expenses stem from compute and storage, which typically align with customer activity. Ideally, you'd want to pay only for the exact resources a customer uses for compute. Similarly, you'd prefer cheaper storage options when embeddings aren't being accessed. By implementing per-customer cost management for their workloads, it should be possible to reduce expenses by 10 to 20 times.
Agents will create more B2B apps than humans in the next decade
Historically, the rate of application development has been constrained by human capabilities. Increasing productivity typically involved hiring more developers or implementing tools that offered modest efficiency gains of 5-10%. However, the advent of AI and the emergence of intelligent agents are set to revolutionize this landscape. We're on the brink of witnessing a surge in B2B app creation. These agent-built applications will need to select their technology stack, with databases playing a pivotal role in this process.
The main restriction to an agent world with millions of apps is database access. Currently, companies are limited by the number of databases they can have due to cost and available compute resources from cloud providers. To fundamentally change this, we need the ability to create unlimited free databases that can fully utilize available resources. This is challenging to build. It requires a true multi-tenant SQL database, rather than provisioning dedicated compute for each database or relying solely on containers or VMs. An ideal database should seamlessly move between deployments. New databases and tenants should start on serverless compute and gradually transition to provisioned compute as they grow. This approach enables a world where agents can experiment with many new applications in parallel on behalf of their users, increasing the chances of success.
Designing a Postgres platform from first principles for AI B2B apps
Customer - the atomic unit of a business
Nile aims to build Postgres from the ground up, focusing specifically on B2B AI applications. The customer or tenant is a core building block of B2B companies—everything revolves around them. It's logical, then, that a data platform built for B2B companies should have the tenant as a native primitive in the database. By defining a customer in the database and extending this concept through to the storage layer, we can address the previously discussed problems at a fundamental level, potentially reducing costs by 10–20x. This approach also simplifies customer workflows that connect to other organizations. For instance, when a premium-tier customer onboards, creating a new customer in the support platform becomes straightforward, as the database can integrate with external APIs. This eliminates the risk of losing customer activity due to failed transactions with third-party services.
Not all customers are created equal. In a typical B2B company, most customers start small and grow over time, while some become power users from the outset. Customer distribution across pricing tiers often follows a pattern: 50% inactive, 30% medium usage, and 20% power users. This distribution can vary based on the company's type and target market.
The revenue each customer brings in differs significantly. Ideally, the cost to serve a customer should reflect this variation. A B2B-focused data platform should accommodate these differences. It should incur no costs for inactive customers, charge based on utilization for medium-usage customers, and provide dedicated compute for power users.
This ability to control infrastructure costs for different customer groups enables companies to operate more efficiently. By aligning costs with customer value, businesses can optimize their resources and improve their bottom line.
Nile’s architecture
Nile has built Postgres from the ground up with tenants/customers as a core building block. The key highlights of our design are:
Decoupled storage and compute. The compute layer is essentially Postgres, modified to store each tenant's data in separate pages. The storage layer consists of a fleet of machines that house these pages. An external machine stores the log, while both the log and pages are archived in S3 for long-term storage.
Tenant-aware Postgres pages. A typical Postgres database comprises objects like tables and indexes, represented by 8KB pages. In Nile, tables are either tenant-specific or shared. Each page of a tenant table belongs exclusively to one tenant, with all records within a page associated with that tenant. This decoupled storage and tenant-dedicated page system allows for instantaneous tenant migration between different Postgres compute instances. Moving a tenant simply involves transferring tenant leadership from one compute instance to another while maintaining references to the same pages in the storage layer.
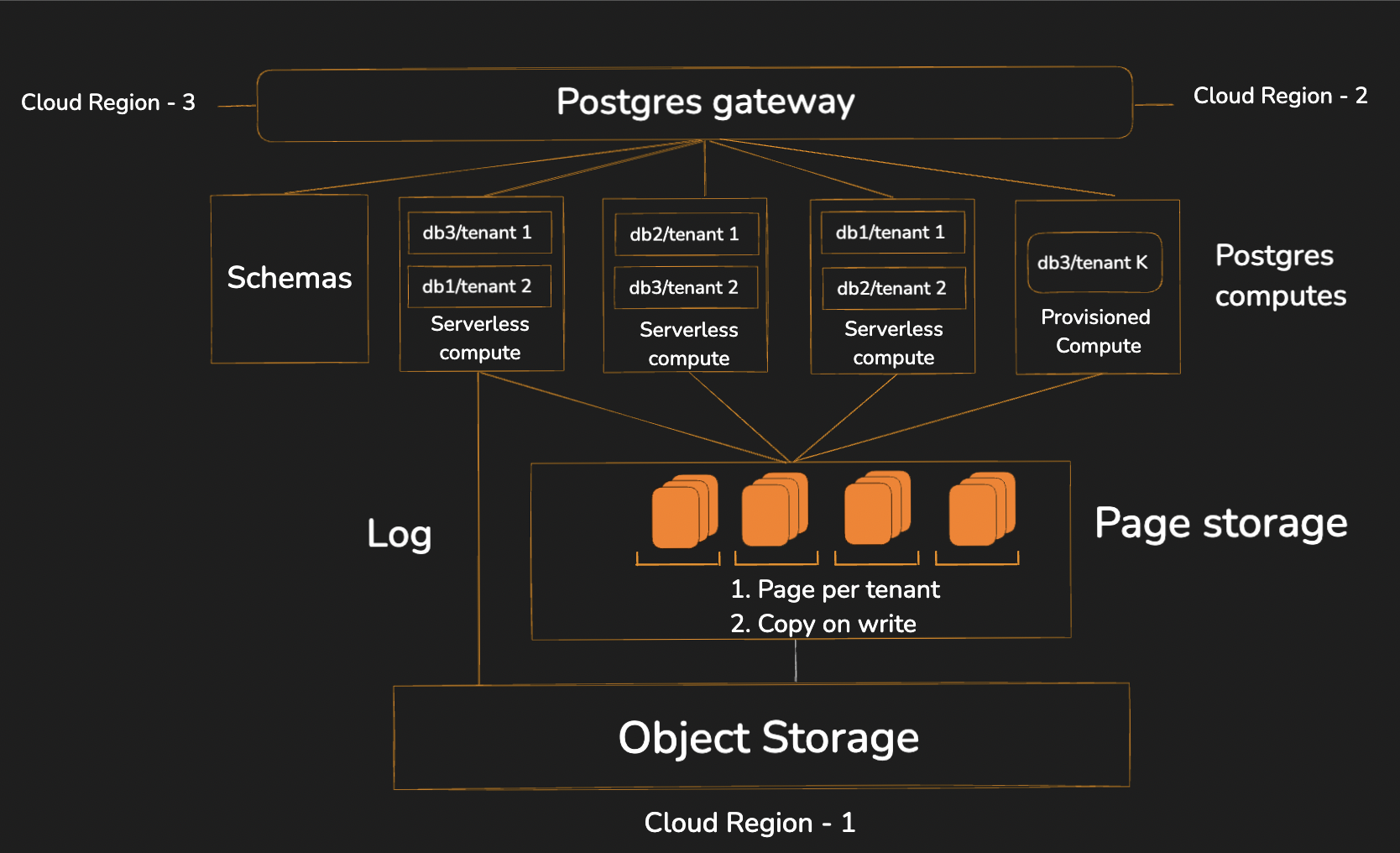
Support for both serverless and provisioned compute. The Postgres compute layer offers two types of compute. Serverless compute is built with true multitenancy, while provisioned compute is dedicated to a single Nile customer. Nile users can have any number of provisioned compute instances in the same database. Tenants can be placed on either serverless or provisioned compute.
Distributed querying across tenants and a central schema store. The distributed query layer operates across tenants and functions between serverless and provisioned compute instances. A central schema store employs distributed transactions to apply schemas to every tenant during DDL execution. This ensures correct schema application and enables schema recovery for tenants during failures.
A global gateway for tenant routing, inter-region communication, and connection pooling. The gateway uses the Postgres protocol to route requests to different tenants. It can communicate with gateways in other regions and serves as a connection pooling layer, eliminating the need for a separate pooler.
Architecture Benefits
This architecture offers numerous surprising benefits. Nile supports various multitenant configurations within a single database, giving users fine-grained control over costs at the customer level. All tenants can be placed on serverless compute for 10–20x lower costs, or a subset can be assigned to provisioned compute for enhanced isolation and security. The system seamlessly scales horizontally across tenants and vertically per tenant, providing virtually limitless capacity.
Unlimited database and virtual tenant databases
In Nile, a database is a logical concept. Our serverless compute allows us to offer a truly cost-effective, multi-tenant solution that provisions new databases rapidly. This enables Nile to provide unlimited databases, even for free tiers. Serverless compute is ideal for testing, prototyping, and supporting early customers. As customers become more active, you can seamlessly transition them to provisioned compute for enhanced security or scalability. Nile's efficiency is remarkable—a new database is provisioned in under a second. The accompanying video demonstrates a typical Nile database creation process and shows the execution of an initial use case.
Tenant placement on both serverless or provisioned compute with 10x compute cost savings
Tenants can now be placed on different types of compute within the same database. The serverless compute is extremely cost-efficient, proving cheaper than provisioning a standard instance on RDS. Built with true multitenancy, it enables Nile to use resources more efficiently across its users. Meanwhile, highly active customers can be moved to provisioned compute. The best part? The capacity needed for this is significantly lower than for an entire database housing all customers.
Support billions of vector embeddings across customers with 10-20x storage savings
The architecture supports vertical scaling for tenants and horizontal scaling across tenants. For vector embeddings, the total index size is divided into smaller chunks across multiple machines. Additionally, since the storage is in S3, Nile can swap a tenant’s embeddings entirely to S3 without maintaining a local cache. The indexes themselves are smaller, and multiple machines can be leveraged to build indexes in parallel. This approach provides lower latency and nearly 100% recall by reducing the search space per customer.
Secure isolation for customer’s data and embeddings
Each tenant in this architecture functions as its own virtual database. The Postgres connections understand tenants and can route to a specific one. Tenant data isolation is enforced natively in Postgres, as it recognizes tenant boundaries without the need for Row-Level Security (RLS). Furthermore, the architecture allows tenants to be moved instantly between compute instances. Performance isolation between tenants can be achieved by relocating them to other compute instances with more capacity without any downtime.
Branching, backups, query insights and read replicas by tenant/customer
Since Postgres understands tenant boundaries, we can now maintain one database for all tenants while executing database operations at the tenant level. This allows us to reproduce customer issues by simply branching the specific customer's data and replaying their workload. If a customer accidentally deletes their data, backups can be restored instantly. We can create read replicas only for customers with higher workloads, saving both compute and storage resources. Moreover, we can now debug performance for specific tenants or customers, eliminating the need to treat the database as a black box.
We are excited once again to be in public preview today. Try out Nile and build your AI B2B apps with a Postgres platform purpose built for it. We are looking forward to all the feedback!