
Many popular business apps that have AI capabilities use the common RAG architectures pattern to generate more relevant and accurate results. Few examples:
- Zendesk allows you to use your solved support tickets as input data to power a copilot that assists the support team in answering future customer support issues.
- Hubspot uses existing information about your customers and past interactions to generate personalized emails.
- Notion uses existing content to help draft and edit documents.
Aside from being RAG apps, these examples all have something else in common: they are all multi-tenant applications, and in any given interaction, they only retrieve data for the current tenant.
This makes sense when you think about it. No marketing team wants to send personalized emails based on customer's interactions with a different company. Customer trust is the most important asset of B2B applications and the addition of AI makes establishing trust even more critical.
In addition to benefits from a user trust perspective, multi-tenant RAG also has performance benefits. RAG architectures have two high-latency steps: Retrieving vectors and LLM inference. Multi-tenant RAG makes vector storage and retrieval significantly more efficient: Searching vectors for a single customer is many orders of magnitude faster and more efficient than searching through all customers and then filtering the result. In many cases the number of vectors per customer is small enough that if you limit search to a specific customer, you can perform exact nearest neighbor search in a reasonable time, which means you benefit from perfect recall. As opposed to approximate nearest neighbor search, using indexes such as HNSW, where you trade-off resources, latency and recall.
In summary, multi-tenant RAG provides privacy, efficiency and accuracy. Now how do we build one?
Storing and retrieving vectors in a nutshell
RAG architectures rely on the ability to efficiently store and search large collections of vectors. The idea is that we take an input text and embed it (turn it into a vector that represents essential properties of that text). The reason we want to turn text into vectors is that we can take two vectors and check the distance between them. This means that for a given input vector, we can search a collection of stored vectors for the K nearest vectors (also known as K nearest neighbors). These vectors represent stored documents that are the most similar to the input text, and persumably most relevant as context for the LLM.
Nearest neighbor search can be done naively, by simply scanning the entire collection of vectors and comparing the distance of each stored vector to the input. This is O(N) operation, but given that vectors are usually large (1536 dimensions is common), it can take a few seconds to search through 10,000 vectors.
Vector indexes are used to speed up searches in larger collections.
Vector indexes are not like b-tree indexes that are common in databases. They improve performance by limiting the nearest neighbor search to subsets of the vectors stored. Subsets that are likely (but not guaranteed!) to contain the nearest neighbors. When using vector indexes we trade off performance for recall - we use parameters to decide how much data we want to search through (details vary depending on the indexing algorithm). Searching through less data means better performance, but higher probability that some relevant results will get missed (worse recall). Because of the loss of recall, searches that use vector indexes are called "approximate nearest neighbor" search, or ANN.
Vector indexes only include data about the indexes themselves, but no additional metadata (also unlike b-trees that can include multiple columns). This means that if we search a vector index, we can't pre-filter the search space based on additional information, we always use the vector index as a whole.
Multi-tenant RAG Architectures
Many vector stores provide solutions for multi-tenancy. Sometimes they have more than one option. Unfortunately, comparing them can be a bit challenging: There is no standard terminology for multi-tenancy in vector stores, so identical solutions can have different names in different vector stores.
If you've ever built any kind of multi-tenant application, these alternatives will look familiar. Lets look the alternatives and the tradeoffs involved, I'll use the terms common in relational databases and mention the terms used by other types of vector stores.
Database per Tenant
On one end of the spectrum, there is the "database per tenant" approach. This approach maximizes isolation and lets you treat each tenant's database as an individual pet with individualized care. It is a good fit if you have a relatively small number of high-paying customers.
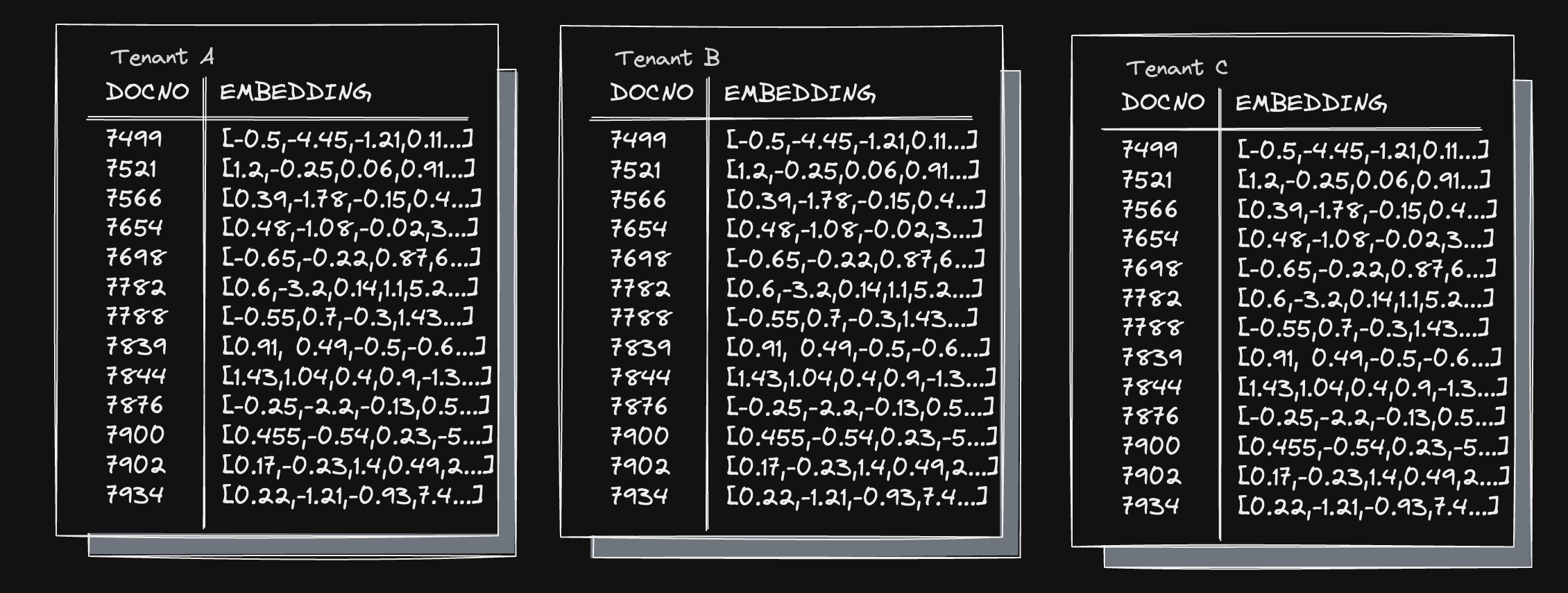
It has the following tradeoffs:
- Resource inefficiency: Even the most active tenant imaginable doesn't use all the resources allocated to a database. Significant portions of memory and CPU are used for maintaining the database - internal data structures, compaction processes, statistics, etc. In multi-tenant databases, this overhead is amortized among all tenants. With a database per tenant, you pay for this overhead for each tenant.
- Client inefficiency: With DB per tenant approach, you need to maintain a connection pool for each tenant for their database. This adds complexity to the application code as well as bloats the memory used by the application. In many cases, developers who choose this architecture also deploy an isolated application stack for each tenant.
- Reporting: If you do need to run any query across all your tenants (lets say, activity report for billing), you'll need to write a script that queries across all these databases and then aggregates the result. You'll likely need to build a data warehouse and ETL process much sooner than you would in the case of multi-tenant database.
- Administration: Any admin operation, such as upgrades or even schema migrations, will need to run across all databases.
Tenant column
At the other end of the spectrum, you place all your tenants in the same DB and use the same tables (sometimes called collections) for all tenants. A tenant_id column (also called field) will be used to determine which row and vector belong to which tenant. Developers are expected to add a filter to each query that will limit the responses to just the current tenant. This approach minimizes overhead and simplifies operations by letting you manage all tenants as identical cattle. It is a good fit if you plan for a very large number (potentially millions) of small and price sensitive tenants, since it has the lowest overhead compared to all alternative solutions.

It has the following tradeoffs:
- low isolation: At the DB layer, tenants are not isolated at all. They share storage, memory, compute and network. Everything. If a developer codes carefully, you won't have any place where data is accidentally leaked between tenants, but this is a fragile guarantee.
- lower scalability: Building and re-building Approximate Nearest Neighbor (ANN) indexes takes more time and resources when you need to index all the data for all tenants in a single index. Similarly, searching one giant index will take longer. As we mentioned earlier, you can't prune an ANN index based on another field before searching it, so you are forced to search the entire index. This also means that the only way to filter data for a single tenant is to first find the nearest neighbors, then filter them based on the tenant, and keep iterating until you find sufficient vectors from that specific tenant.
- no tenant-level admin: Because all the tenants are placed in the same database, operations such as upgrades or restoring backups will always affect all tenants. If some tenants need to stay on an old version for some reason, this will be very difficult to solve.
Hybrid options
The alternatives above represent two extremes - isolation and scalability on one side, ease of use and efficiency on the other. Some vector stores also offer alternatives between these two extremes. This involves putting tenants in the same database and adding isolation by separating tenants into their own schema (also called namespaces), tables (aka collections) or partitions. Each one of these options provide additional isolation but also some additional downsides. These options also have limits on the number of tenants, because they all represent additional objects in the database. The limits will range from a few thousands to around 100,000, depending on the exact solution and on the database.
Multi-tenant RAG with Nile and pgvector
Nile is Postgres, re-engineered for multi-tenant applications. When you use Nile, you'll notice that the developer experience is very similar to the "tenant column" architecture. You'll have a tenants table and you will need to add tenant_id column to each table that holds tenant-specific data or vectors.
However, behind the scenes, Nile stores tenant's data in their own virtual tenant databases and handles the routing of queries to the right destination. This way, Nile enforces isolation and provides additional capabilities such as placing tenants on dedicated or shared compute. In order to provide these capabilities, Nile checks that developers follow policies such as: "every insert must specify the tenant ID" and "mixing different tenants in one transaction is not allowed", these rules are guardrails that help developers build secure and private applications.
These capabilities are supported by Nile for any table and any type of data. For vectors, Nile integrates with pgvector - Postgres' popular vector type. pgvector provides optimized vector types for both dense, quantized and sparse vectors, as well as various distance functions and vector indexes (flat, IVFFlat, HNSW).
Combining a vector store with a relational data structure is very powerful. You can:
- Query vector data using familiar SQL syntax
- Use your favorite clients, SDKs and ORMs on vector data
- Join vectors and documents with related data - relevant metadata, summaries, other documents with the same context.
- Efficient B-Tree indexes on metadata for additional filtering
- ACID compliance. You can store all related documents, metadata and embeddings in one transaction, to avoid missing or out of sync information.
Let's take all the examples of multi-tenant RAG applications that I mentioned in the beginning of this blog: Zenefits, Hubspot, Notion. They all combine RAG with application data in a seamless user experience. Using Postgres to store both application data and vectors is a simple and efficient way to implement the same experience.
Next, we'll look at a few examples of using Nile for multi-tenant RAG. We'll implement the same similarity search in 5 different languages and frameworks.
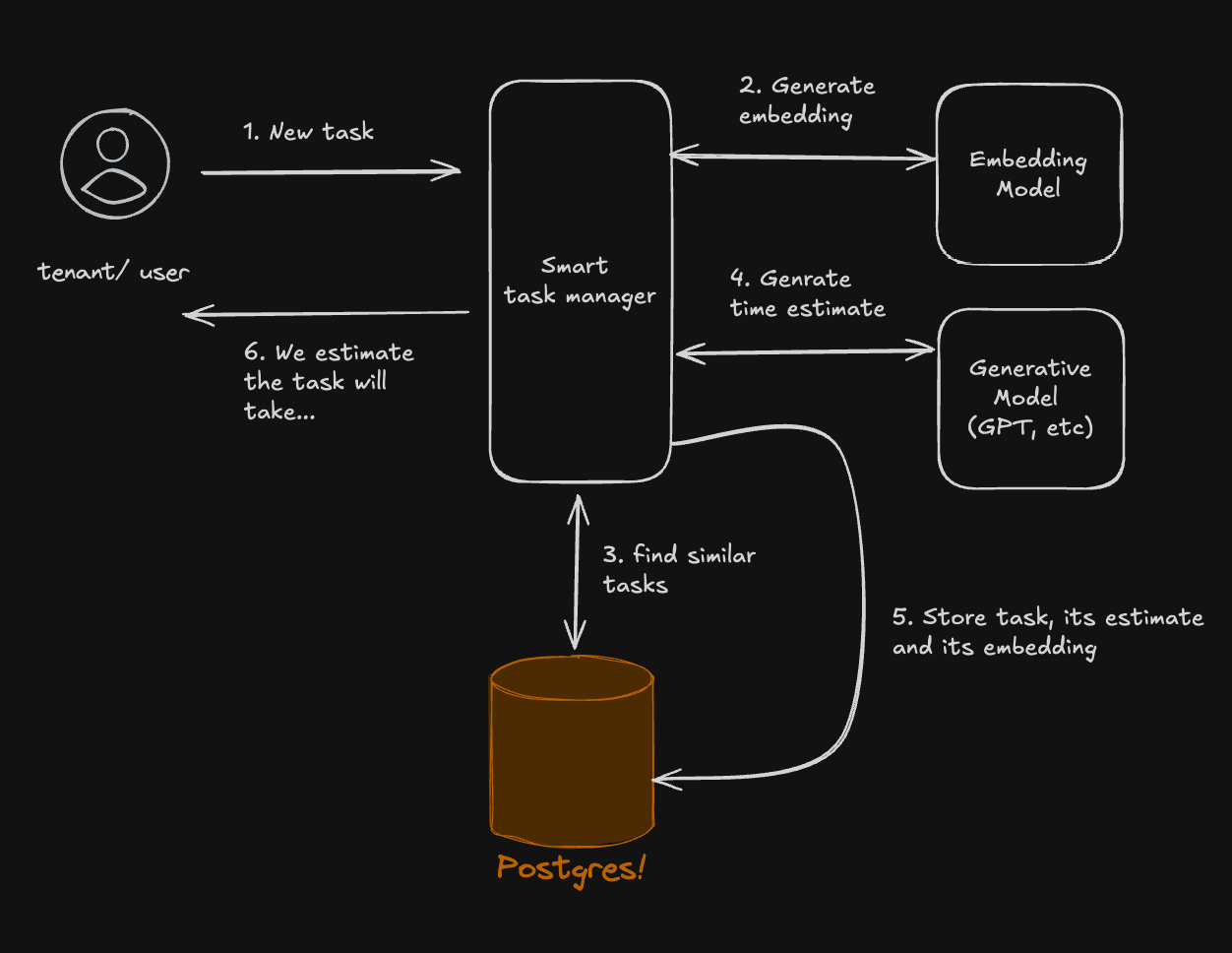
In all these examples, we are building a smart task manager that uses past tasks, their time estimates and an LLM to estimate how long new tasks will take. To implement this, we insert tasks with embeddings and later search for similar tasks based on their embeddings. Naturally, we don't want to mix tasks between tenants.
Using SQL
You can use Nile exactly as you'd use pgvector, except that you'll want to let Nile know which tenant you are working on. For example:
-- creating a table to store wiki documents for a Notion like
-- SaaS application with vector dimension of 3
CREATE TABLE todos(
tenant_id uuid,
title varchar(256),
embedding vector(3),
estimate text
);
-- store vector for a tenant
-- you'll typically use an embedding model to generate the vector
-- in the real world these vectors have hundreds of floating point dimensions
INSERT INTO todos (tenant_id,title, embedding, estimate)
VALUES ('018ade1a-7843-7e60-9686-714bab650998','feed the cat', '[1,2,3]', '5 minutes');
-- Find 10 nearest neighbors, but only for documents that belong to one tenant
SET nile.tenant_id = '018ade1a-7843-7e60-9686-714bab650998';
SELECT * FROM todos
ORDER BY embedding <=> '[3,1,2]'
LIMIT 10;
Using the Nile SDK (Typescript / Javascript)
Using Nile SDK is very similar. You still write plain SQL. Nile SDK will handle connection pooling and setting the tenant ID where needed:
// grab a connection to a virtual tenant database
const tenantNile = await configureNile(params.tenantid);
// get similar tasks, no need to filter by tenant because we are already in the tenant context
const similarTasks = await tenantNile.db.query(
`SELECT title, estimate FROM todos
ORDER BY embedding <-> $1
LIMIT 10`,
[embeddingToSQL(embedding)],
);
You can find full example applications using our SDK with NextJS or NodeJS.
Using Drizzle (Typescript)
Drizzle is a popular Typescript ORM with great support for vector types. It is extensible, so you can wrap each transaction in a bit of code that injects the tenant_id. Once we do that, performing nearest neighbor search will look like this:
const similarity =
sql < number > `(${cosineDistance(todoSchema.embedding, embedding)})`;
// get similar tasks, no need to filter by tenant because we are already in the tenant context
const similarTasks = await tenantNile(async (tx) => {
return await tx
.select({ task: todoSchema.title, estimate: todoSchema.estimate })
.from(todoSchema)
.where(lt(similarity, 1))
.orderBy((t: any) => desc(similarity))
.limit(3);
});
We defined a similarity method using cosine distance between our document embedding and the embedding column in the table, and then use Drizzle client objects to build and execute the query. Drizzle supports all the distance metrics available in pgvector. You can find the rest and additional examples in Drizzle documentation. If you are interested to try, we have a full example application that uses Drizzle with Nile and pgvector.
Using Psycopg (Python)
Psycopg is Python's most popular Postgres client. It has an extension for pgvector.
You use Psycopg with the same SQL syntax that we've seen in the SQL example above. The only difference is that we pass the vector as a parameter, per psycopg best practices:
conn = psycopg.connect(os.getenv("DATABASE_URL"))
cursor = conn.cursor()
cursor.execute('set nile.tenant_id = %s', (tenant_id,))
query = sql.SQL(
"""
SELECT title, estimate
FROM todos
ORDER BY %(query_embedding)s::vector <-> embedding
LIMIT 3
""")
cursor.execute(query, {"query_embedding": query_embedding})
return cursor.fetchall()
Using SQL Alchemy (Python)
SQL Alchemy is a Python ORM and works quite similarly to Drizzle. It integrates well with FastAPI, so tenant-specific connections are injected as dependencies into route handles that work with tenant data. With the tenant-specific connections, I can perform similarity search for each tenant as follows:
# get similar tasks, no need to filter by tenant because we are already in the tenant context
similar_tasks_raw = (
session.query(Todo)
.filter(Todo.embedding.cosine_distance(query_embedding) < 1)
.order_by(Todo.embedding.cosine_distance(query_embedding)).limit(3))
return [{"title": task.title, "estimate": task.estimate} for task in similar_tasks_raw]
The session object is already set with the tenant ID, thanks to a tenant-aware middleware. We used pgvector integration with sqlalchemy to add embedding column to the Todo model with vector type. Then we can call its cosine_distance function as you see above.
You can browse the full example here.
Using LlamaIndex (Python)
Nile has a LlamaIndex integration, which lets you create tenant-aware vector stores in LlamaIndex and use them with LlamaIndex's simple RAG SDK and workflows. You can really see how LlamaIndex simplifies things, because you never need to explicitly search for nearest neighbors. You initialize an index from a table on Nile, and simply prompt the LLM. LlamaIndex and Nile integration handle it all behind the scenes.
# Initialize an index from a table on Nile - this is done once when app starts
self.vector_store = NileVectorStore(
service_url=os.getenv("DATABASE_URL"),
table_name="todos_embedding",
tenant_aware=True,
num_dimensions=768
)
self.index = VectorStoreIndex.from_vector_store(self.vector_store)
# create a query engine for specific tenant, this is a light wrapper
query_engine = self.index.as_query_engine(vector_store_kwargs={
"tenant_id": str(tenant_id),
})
# Just prompt with the task you need to estimate
response = query_engine.query(
f'you are an amazing project manager. I need to {text}. How long do you think this will take? '
f'respond with just the estimate, no yapping.'
)
You can find the full example of using LlamaIndex to build multi-tenant RAG application here.
Summing things up
In this blog, we explored how multi-tenant Retrieval-Augmented Generation (RAG) is used in AI-powered B2B applications like Zendesk, HubSpot, and Notion. These apps retrieve data specific to each tenant, ensuring both data isolation and improved performance. We dive into different multi-tenant RAG implementation strategies, from the extremes of DB per tenant to using a tenant column in a single database. We also showcase how Nile's Postgres-based solution combines the simplicity of tenant-column architecture with powerful isolation, enabling efficient and secure AI experiences. And we demonstrated its use in a variety of languages and frameworks.
Ready to build your multi-tenant RAG app? Get started with Nile.
Last but not least, huge thanks to Vicki Boykis who reviewed early drafts of this blog. Her detailed feedback and suggestions made this blog so much better. The remaining mistakes and confusing explanations are all mine.