
When we need to describe Nile in a single sentence, we say "PostgreSQL re-engineered for multi-tenant apps". By multi-tenant apps, we mean applications like Stripe, Figma, Twilio, Notion, Workday, and Gusto - here a large number of customers is served from a shared application stack. In these types of applications, a key architectural challenge is deciding how to store data for each customer.
What makes this data architecture especially challenging is the tension between two opposing needs. On one hand, requirements like latency, compliance, and scalability often push toward placing tenants on multiple databases. On the other hand, a single database offers a significantly better developer experience and cost model. Broadly speaking, there are two main approaches.
The first is database per tenant (or sometimes schema per tenant:
This architecture provides isolation and flexibility but requires more resources and effort to operate. The other approach is to place all tenants in the same shared schema and add a tenant identifier to every table:

This approach is simple and cost-effective, which is why most new applications start here. However, over time, it can run into scalability issues and difficulties in adapting to individual customer needs and requirements.
That's why, no matter where you start, you eventually end up with a hybrid model. In a typical hybrid architecture, the database is distributed out through sharding. Most tenants are placed on shared shards, while larger and more demanding customers are allocated dedicated shards.
Scale isn't the only reason to use the hybrid architecture. A more common reason is the need to store data in multiple regions. Tenants always prefer low latency, which requires data to be placed close to them or in a specific region. Some tenants also have compliance concerns that requires storing their data in specific countries.
Both hybrid and db-per-tenant architectures require a way to propagate the DDL changes to all the tenants instantaneously with great devex and high reliability.
Nile provides all the developer experience, operational simplicity and cost benefits of a single database while also achieving the isolation and per-tenant control benefits of a db per tenant architecture.
The number of databases you need to build a multi-tenant app is one.
This one database contains many "virtual tenant databases" - one per tenant. These virtual tenant databases can be placed on multiple physical Postgres databases. Tenants can be placed on shared compute (which may be sharded depending on the workload), or on dedicated compute. Regardless of how the tenant databases are organized, developers connect to one database and work as if everything were in a single shared schema.

Our goal is to support any number of virtual databases, distributed across a number of physical PostgreSQL instances, while still providing the seamless developer experience of a single schema shared by all tenants. DDLs (Data Definition Language commands) are SQL commands that modify the schema - things like CREATE TABLE, ALTER TABLE and DROP INDEX. Our goals for the developer experience with DDLs are:
- Each DDL applies to all tenants concurrently
- Behaves exactly as it normally would in Postgres. This includes supporting transactions with DDL and all the transactional guarantees (which we consider one of PostgreSQL's best features). It also includes performing the DDL synchronously from the user point of view, when the
CREATE TABLEcommand returns, the table must be visible and usable for all tenants, regardless of their placement. - The fact that each DDL executes over multiple virtual databases and physical instances should be completely transparent to developers
To deliver on these requirements, Nile built pg_karnak. pg_karnak is a distributed DDL layer that operates across tenants and postgres instances - soon to be open sourced. It includes an extension that intercepts DDLs, a transaction coordinator to apply schemas to every tenant during DDL execution and a central metadata store. This ensures correct DDL application and enables recovery for tenants in case of failure.
In this blog, we'll dive into the architecture and implementation of pg_karnak. We'll start with a high-level overview of the architecture and walk you through the green-path flow of executing a simple DDL. Then we'll dive into the details of how we solved the three most challenging problems with distributed DDLs: transactions, locks and failure handling. Along the way, we'll share some tips and tricks we used in building our Postgres extension -- these might come in handy if you decide to write your own extensions.
So, grab a coffee, and let's get started!
Distributed DDL architecture walkthrough
We've implemented our distributed DDL system using two main components:
pg_karnakextension: This extension is loaded into every Postgres instance. It is responsible for intercepting DDL statements, extracting key information, and initiating the distributed transactions.- Transaction coordinator: This is a stand-alone service that distributes the DDL statements to all relevant databases and ensures that each DDL is either applied successfully to all databases or to none of them.
To understand how these components work together to execute a DDL statement, let's look at what happens when a user connects to their Nile database and issues a CREATE TABLE command. This command is sent from the client to one of the Postgres instances, where it is intercepted by the pg_karnak extension.
Intercepting DDL with processUtility_hook
In order to intercept the DDL before it executes, pg_karnak uses the processUtility_hook. To understand why and how our extension uses this hook, we first need to explain what a utility command is and how PostgreSQL handles them.
In Postgres terms, a "utility" is any command except SELECT, INSERT, UPDATE and DELETE. This includes all DDL commands as well as other commands like COMMIT, NOTIFY or DO. When Postgres recieves a utility command, it uses ProcessUtility(..) method to process it. This is a simple wrapper that looks like this:
if (ProcessUtility_hook)
(*ProcessUtility_hook) (...);
else
standard_ProcessUtility(...);
This method checks if there are any extensions that want to process the utility command before Postgres runs its standard processing. The pg_karnak extension provides such a hook and, as a result, is called before Postgres processes any command. This is incredibly useful because processUtility_hook is triggered for nearly everything that isn't a SELECT or a DML, giving us a single entry point for almost everything we need to handle.
Once we finished processing the command, it is our responsibility to call standard_ProcessUtility, so that Postgres can continue its normal flow. A bit off-topic, but in case you're curious: standard_ProcessUtility method is essentially a gigantic switch statement that routes every one of the 60+ utility commands to their appropriate handler.
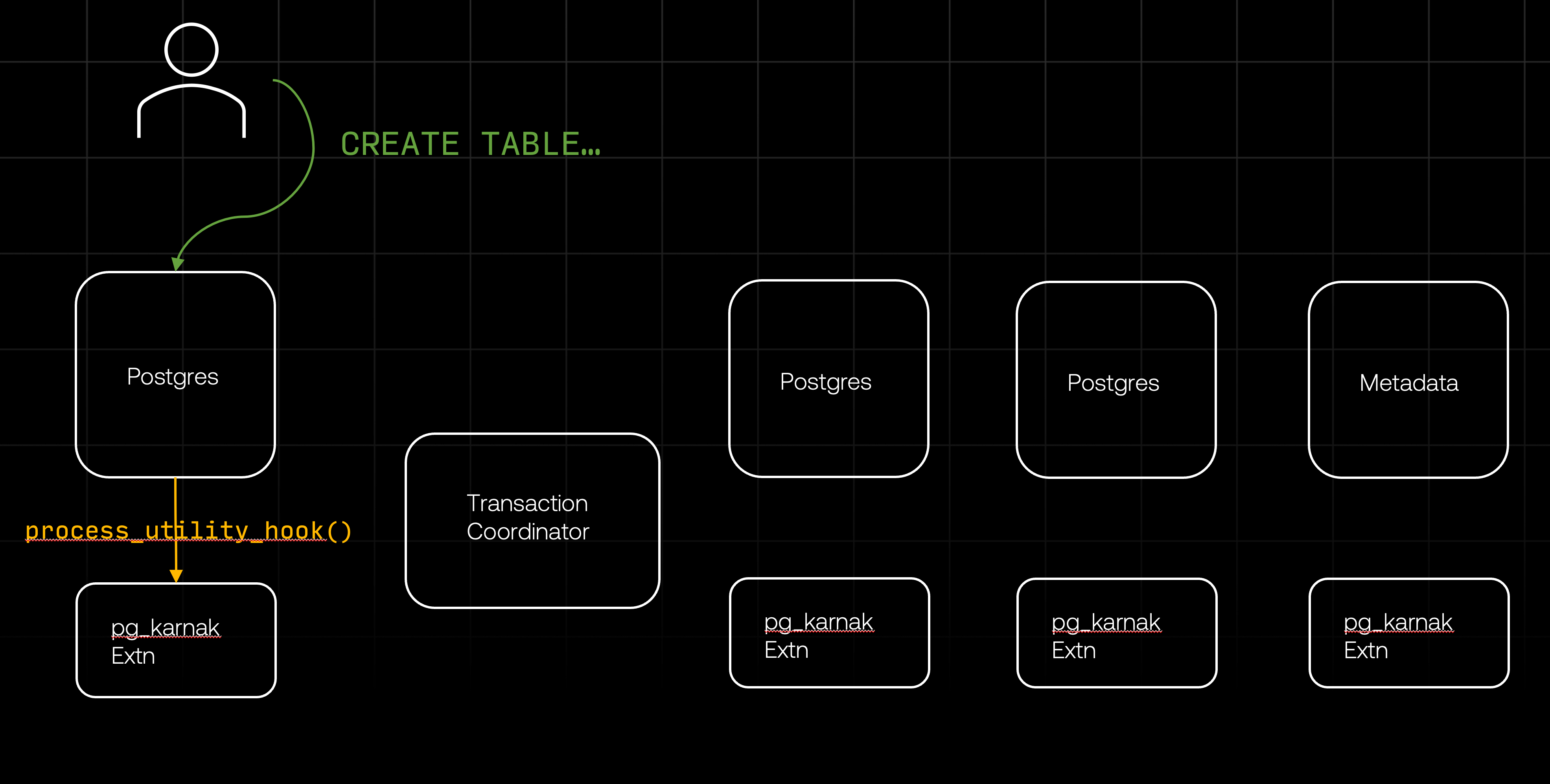
So, our extension gets called with a utility command. What happens next? At this point, it needs to perform a few tasks:
- Check that the command is one we want to handle There are many utility commands and we only handle a subset. Commands that we don't handle, like
FETCH,SHOWorDISCARDare just passed directly tostandard_ProcessUtility. - Raise error for unsupported DDL. Nile has specific restrictions on the type of relations we allow. For example, primary keys must include the
tenant_idcolumn, andtablespacecommands are not supported at all (Nile handles these automatically). - Determine which locks the DDL requires.
- Begin a distributed transaction (only needed if this is the first DDL in a transaction)
- Ask the transaction coordinator to distribute the locks
The reason we extract the locks and distribute them early in the process is to minimize the time spent holding a lock and reduce the risk of lock conflict. Most DDL statements require an ACCESS EXCLUSIVE lock, which not only prevents any queries from accessing the table in question while the DDL is executing but also prevents any new queries from accessing the table while the DDL is waiting to acquire the lock. To minimize the risk and the time spent while holding the lock, Nile attempts to acquire the necessary locks - with a short lock timeout - on all relevant databases before starting to execute the DDLs. If the lock acquisition fails on any database, the DDL will return an error rather than continue waiting for the lock.
Acquiring locks with a short timeout before executing DDLs is considered a best practice in Postgres for the reasons we just explained. Nile's distributed DDL implement this best practice for our users.
Transaction coordinator
Once the pg_karnak extension determines the necessary locks, it calls the transaction coordinator to start a transaction (if necessary) and distribute the locks.
Starting the transaction is straightforward: the coordinator maintains open connections to all databases and simply sends each one a BEGIN command.
Distributing the locks works similarly. The coordinator sends all databases the commands required to acquire the locks (more details in the section on locking). To avoid deadlocks, we ensure that locks are always acquired in the exact same order - both in terms of the sequence of databases and the order of locks within each database. This guarantees early failure in the event of conflicts and prevents situations where two concurrent transactions are each waiting for the other to release a lock on a different database.
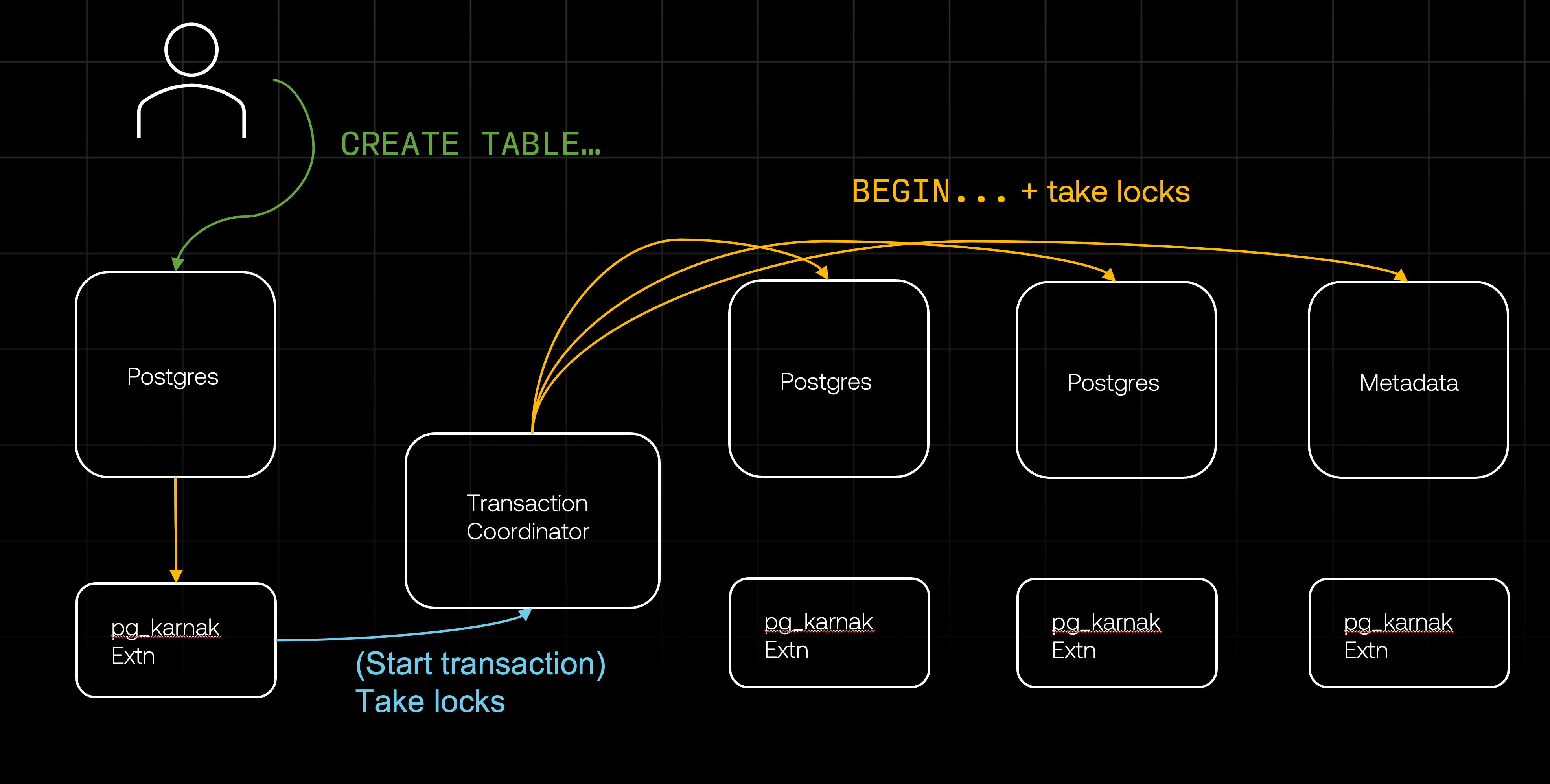
Once the locks are acquired, the pg_karnak extension instructs the coordinator to distribute the DDL itself. But first, it has to make sure the DDL is fully qualified. CREATE TABLE todos (...) can be ambigous - in which schema should Postgres create the table? This depends on the current search_path config and the existing schema, which can change on some databases while the DDL is distributed (for example, if there's a concurrect CREATE SCHEMA operation). To avoid an inconsistent result, pg_karnak modifies the DDL and makes sure all objects are fully qualified. Only then it sends the DDL to the transaction coordinator for distribution.
While the coordinator sends the DDL command to all other databases, the original extension that first received the DDL proceeds to call standard_ProcessUtility and process the DDL locally.
Meanwhile, each remote database receives the DDL command. Since every database runs our extension, these DDL commands are intercepted by the extension on each database. It is crucial that the extension does not attempt to redistribute these DDLs, as doing so would lead to an infinite loop. Therefore, the extension has to recognize that these DDLs were sent by the transaction coordinator and can be passed directly to standard_ProcessUtility. To achieve this, we use a configuration (GUC) set when the transaction coordinator initializes the transaction. This configuration indicates to the extension that it doesn't need to reprocess the DDLs that follow, as they have already been validated by the originating extension and distributed by the coordinator.
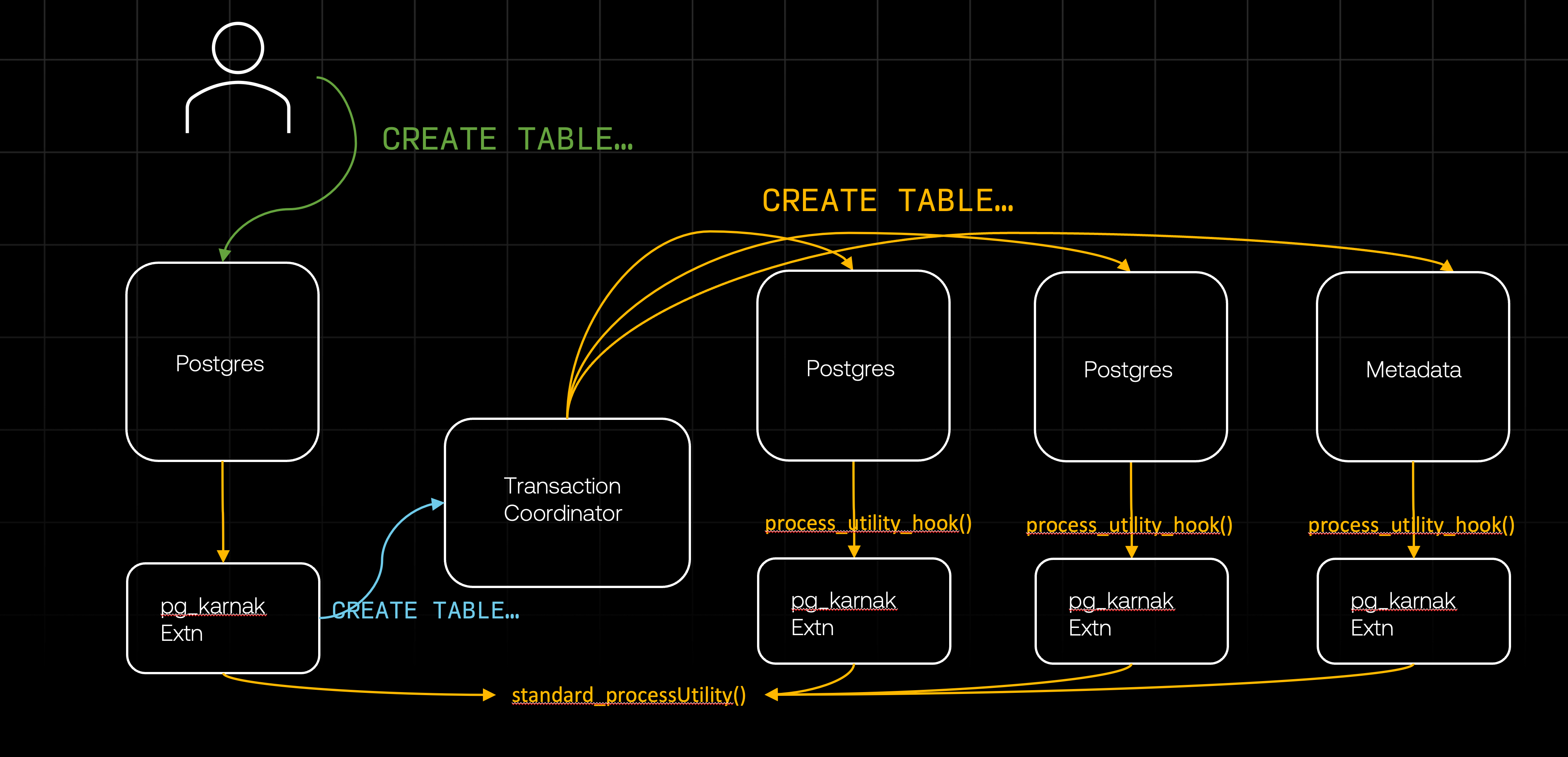
Once all the databases finished processing the DDL, the coordinator notifies the originating extension of successful completion. The extension, which has already finished processing the DDL locally, can return the response to the client. At this point, we have successfully executed a distributed DDL.
Or almost. We still need to commit the transaction. To maintain atomicity guarantees, it must commit on all databases or none at all. Let's look in detail at how we commit the distributed transaction.
Transactions
You may recall from an earlier section that BEGIN, COMMIT, ABORT and ROLLBACK are all utility commands. So it might seem like we could handle transactions by having our processUtility_hook intercept these commands and implement distributed transactions. This approach is tempting, but it has some critical drawbacks:
- Intercepting every
BEGINwill be very costly in a transaction-heavy database. Most of this effort will be wasted, as an OLTP system processes billions of DML transactions for every DDL. - Transactions can be implicit - standalone DDL statements are treated as transactions, for example. We won't always have a
BEGINto intercept, so we must treat each DDL as potentially starting a transaction. - Intercepting a
COMMITonly gives us a single point to intercept - when theCOMMITcommand is sent. However, distributed transactions require a two-phase commit, which can't be implemented with this single hook.
Fortunately, PostgreSQL provides a better mechanism for extensions to hook into the transaction lifecycle: XactCallback (pronounced "transaction callback").
This callback is triggered on various events within the transaction lifecycle, with an enum parameter that specifies which event occured. The events that we are interested in are:
XACT_EVENT_PRE_COMMIT- This event occurs just before the commit itself. The callback method is allowed to return an error while processing it. If an error is returned, Postgres will abort the transaction and force a rollback.XACT_EVENT_COMMIT- This event happens after the commit. At this point, the callback is not allowed to return an error. Regardless of what happened, it must reach a healthy and successful state since the client will recieve a confirmation that the transaction was successfully committed.XACT_EVENT_ABORT- This event is triggered when the transaction is aborted and the callback needs to handle the rollback.
The pg_karnak extension maps these events into a distributed two-phase commit (2PC) process.
The first task for the extension is to detect when to start a distributed transaction. This is simpler than it sounds: if processUtility_hook is called with a DDL and there's no currently active transaction in the same session, then the extension tells the transaction coordinator to begin a transaction. There's no scenario where a DDL is processed without an active transaction. If a transaction is already in progress for the session, the extension will continue to process all arriving DDLs.
This process continues until XactCallback is triggered with XACT_EVENT_PRE_COMMIT event, which indicates that Postgres is preparing to commit the transaction. This callback is triggered regardless of whether there is an explicit transaction with an explicit COMMIT or Postgres is committing an implicit transaction. The callback handles the pre-commit event by notifying the transaction coordinator and passing along the transaction ID.
The transaction coordinator then sends the PREPARE TRANSACTION command to all relevant databases.
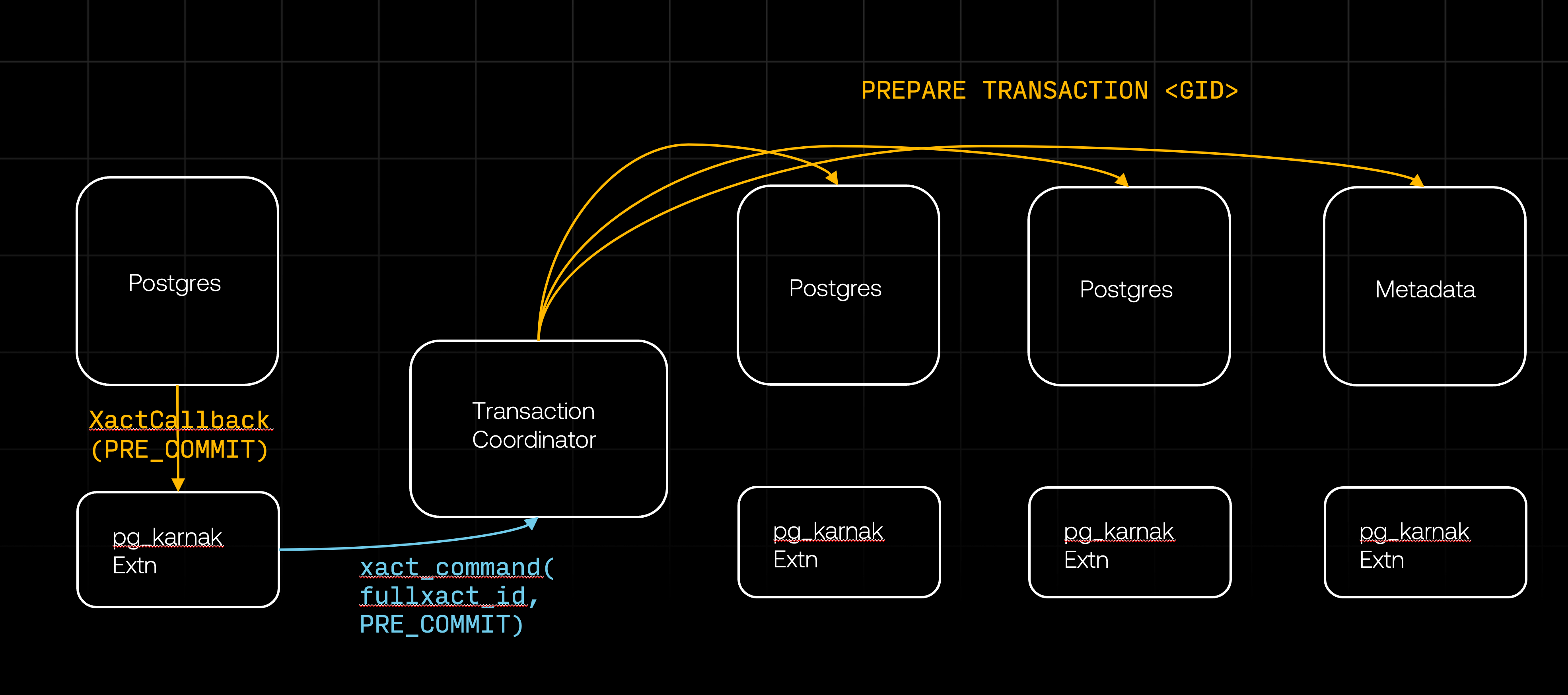
According to the Postgres documentation, the PREPARE TRANSACTION behaves as follows:
PREPARE TRANSACTIONprepares the current transaction for two-phase commit. After this command, the transaction is no longer associated with the current session; instead, its state is fully stored on disk, and there is a very high probability that it can be committed successfully, even if a database crash occurs before the commit is requested.
Once prepared, a transaction can later be committed or rolled back withCOMMIT PREPAREDorROLLBACK PREPARED, respectively. Those commands can be issued from any session, not only the one that executed the original transaction.
The phrase "very high probability that it can be committed successfully" may sound a bit less reassuring than we'd like. In practice, it means that PREPARE TRANSACTION is successful when it has persisted the transaction state to disk. The transaction will be committed successfully unless the database crashes and the files or disks where it is stored are completely lost. If this happens, it is likely that much more than just this one transaction is lost. In other scenarios, such as running out of memory, the "prepared" state is preserved and the transaction can be committed if COMMIT PREPARED is retried, even from other sessions.
Barring this very rare scenario, PREPARE TRANSACTION has all the properties we need from the first phase of two-phase commit: It is durable, and the prepared transaction can be committed or rolled back from any session. This ensures that once we successfully prepared transactions on all databases, we can reach a consistent state no matter what else happens. Additionally, if PREPARE TRANSACTION fails, it will automatically trigger a rollback on the database where it failed.
Let's assume that all databases successfully prepared their transactions for commit (we'll cover the failure scenarios in the next section). This succesful preparation completes the first phase of the two-phase commit (2PC). The XactCallback on the originating database will then return successfully, allowing Postgres to proceed with the transaction commit. The XactCallback will be triggered once more, this time with XACT_EVENT_COMMIT event. During this phase, the first action the pg_karnak extension takes is to reset its state - such as cleaning up the transaction in progress - so that the next DDL command will begin a new transaction. This cleanup comes first to simplify error handling. Then the extension commits the transaction locally and instructs the transaction coordinator to send the COMMIT PREPARED command to all databases, which commits all the prepared transactions in the remote databases.
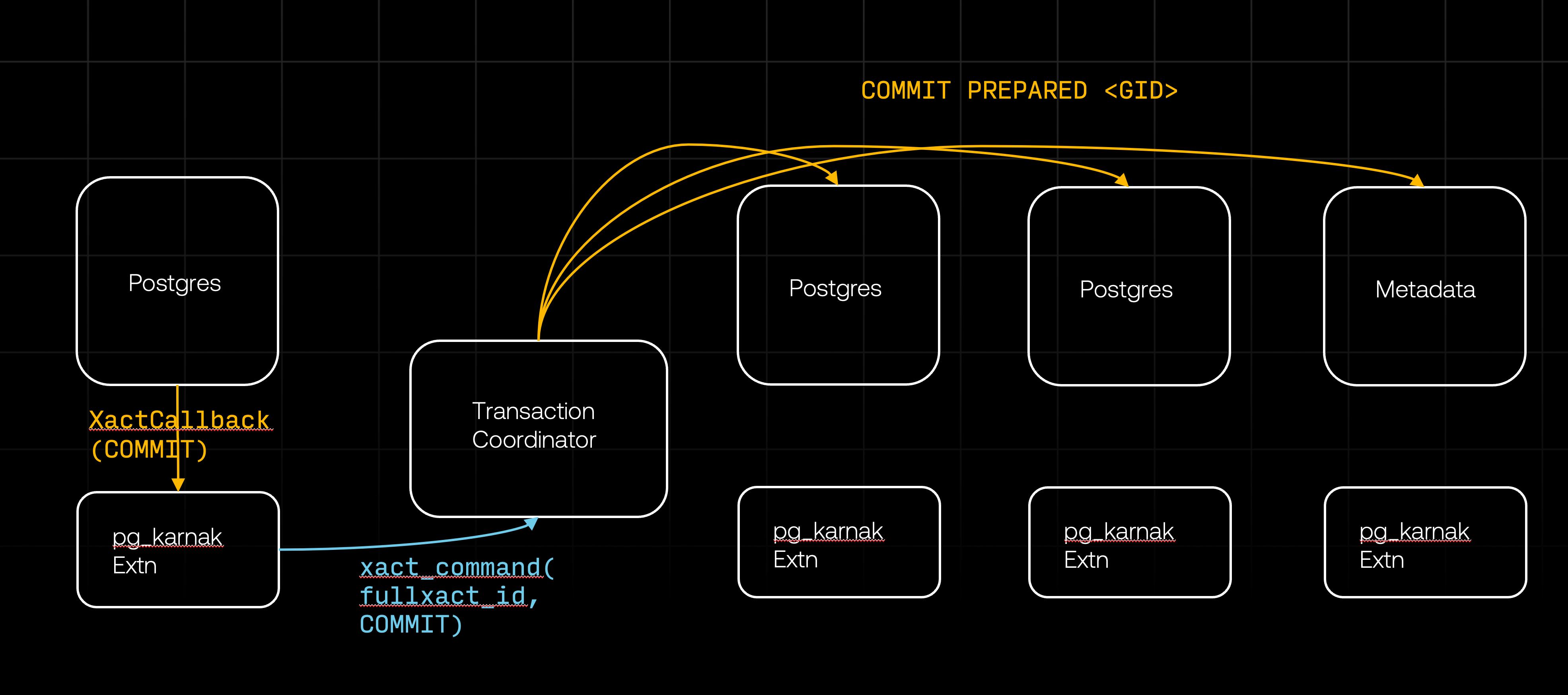
Once all the databases commit, the second phase of the 2PC is completed, and the distributed transaction is fully committed. We still need to discuss what happens if they don't commit successfully. But before diving into that, lets take a quick detour and look at how we handle locks.
Locks
If you recall, the first step the pg_karnak extension takes toward distributing a DDL is to determining the locks the DDL will need and attempt to acquire them on all relevant databases. We approach this with 3 simple goals in mind:
- Fail early: If a DDL is going to fail due to inability to acquire locks, we want to detect this before performing any resource-intensive operations.
- Minimize blocking: Many DDLs require
ACCESS EXCLUSIVElock and attempts to acquire this lock will block other sessions, even while waiting. In a busy OLTP system, it is important to minimize such blocks. - Avoid deadlock: We want to prevent situations where two sessions are stuck waiting for each other to release a lock, resulting in neither making progress.
To fail early, we ensure all the necessary locks are acquired as the first step in processing a DDL, even before executing the DDL locally. While we could acquire locks in parallel, this approach could be wasteful - imagine building an index on a large table locally only to roll it back because we couldn't acquire the lock on a table in one of the remote databases.
The pg_karnak extension determines the required locks by analyzing the DDL. ALTER and DROP are fairly straightforward: we acquire locks on the objects being modifying. DROP CASCADE may require identifying and locking all dependent objects. In most cases, acquiring the lock is simply a matter of sending LOCK TABLE <table name> IN <lock level> MODE with the appropriate lock level for the DDL. For instance, before distributing DROP TABLE todos, the transaction coordinator must first distribute LOCK TABLE todos IN ACCESS EXCLUSIVE MODE...
However, LOCK TABLE only applies to tables. Some DDLs, such as DROP SCHEMA, require locking other objects. Postgres has internal methods for locking any object, so we added logic to handle this in our extension::
if (is_rel)
LockRelationOid(objid, lockmode);
else
LockDatabaseObject(classid, objid, objsubid, lockmode);
When locking a relation, such as a table or a view, we use LockRelationOid, the Postgres method underlying LOCK TABLE. For other objects, we use LockDatabaseObject and directly lock the object.
This approach works well for local locks, but how do we distribute it? We wrapped the object lock acquisition logic in a function within the pg_karnak extension and exported it:
PGDLLEXPORT Datum nile_ddl_objectlock(PG_FUNCTION_ARGS);
PG_FUNCTION_INFO_V1(nile_ddl_objectlock);
The transaction coordinator can then send SELECT nile_ddl.nile_ddl_objectlock(...) to all the databases and acquire all the necessary locks for the DDL.
When the transaction coordinator distributes the actual DDL, Postgres will try to re-acquire the locks. Because the DDL execution occurs in the same session as the initial lock acquisition, and the locks are on the same objects at the same level, the DDL processing will succeed in acquiring the locks - guaranteed.
So far, we discussed acquiring locks on existing objects, but what about cases like CREATE TABLE? Table creation also requires locks to prevent conflict between sessions trying to create the same table. How do we lock a table that does not exist yet?
Normally Postgres uses the data dictionary for this. It inserts a row for the new table into several pg_catalog tables, with the table name added to unique indexes. If another session tries to insert a row with the same name, it will block and fail if the first session commits. Unfortunately, this method isn't usable for us. Row locks cannot be re-acquired, which means the actual DDL would block on the same lock during execution.
Another option is using "advisory locks", which are application-defined locks managed by Postgres. However, advisory locks lack namespaces and are identified solely by their ID. This introduces a risk of collision if a user's application also uses advisory locks. It would be problematic if parts of an application were blocked unexpectedly due to table creation.
To resolve this, we explored PostgreSQL's lock implementation. All the locks we discussed so far - table, object and advisory - use the low-level LockAcquire method. The method signature is:
extern LockAcquireResult LockAcquire(const LOCKTAG *locktag,
LOCKMODE lockmode,
bool sessionLock,
bool dontWait);
The LOCKTAG parameter identifies the lock target and includes the lock type and four integers for specific identifiers. Their meaning depends on the lock type - these can be object ID, block number, row id, transaction ID, etc.
Looking at the enum that specifies the types of locks, you'll all the familiar types we discussed and a few more:
typedef enum LockTagType
{
LOCKTAG_RELATION, /* whole relation */
... /* left out more locks, check the PG source code for details */
LOCKTAG_USERLOCK, /* reserved for old contrib/userlock code */
LOCKTAG_ADVISORY /* advisory user locks */
} LockTagType;
LOCKTAG_USERLOCK is reserved but no longer in use, so we repurposed it for our needs. Using the four LOCKTAG fields, we identify the table with a database ID, schema ID, and a hash of the table name (since a name doesn’t fit in an integer):
locktag.locktag_type = LOCKTAG_USERLOCK;
locktag.locktag_field1 = logical_db_id;
locktag.locktag_field2 = schema_name_hash;
locktag.locktag_field3 = object_name_hash;
res = LockAcquire(&locktag,AccessExclusiveLock…);
As with other locks, we wrapped this user-lock acquisition logic in a method and exposed it through the pg_karnak extension. Before distributing CREATE TABLE todos() the transaction coordinator distributes SELECT nile_ddl.nile_ddl_userlock(...) to acquire the locks necessary for table creation.
To avoid lock contention, long blocking times, and deadlocks, we implement several safety measures:
- Acquire locks in a consistent order across all databases.
- Always start lock acquisition with the same database to prevent distributed conflicts while detecting local conflicts early.
- Set
LOCK_TIMEOUTto a low value for all distributed DDL operations.
Even with all the precautions, things can still go wrong. In the next section we'll discuss our failure handling mechanisms.
When things go wrong
Failure handling in distributed systems must be part of the architecture, it cannot be added as an afterthought. This is why we designed our architecture around tried-and-true primitives - Postgres' transaction mechanism and two-phase commit (2PC). These provide the basic primitives needed to safely handle failure scenarios. In this section, we will describe key failure scenarios and how the components outlined earlier address them.
If you were to list all the failure scenarios - considering the state of the database, the types of failures that can occur, and the possible ways to handle each - you would end up with a long and complicated list. We performed this exercise and identified dozens of possible scenarios. This was useful for ensuring that we approached the problem comprehensively and later for testing our handling of these scenarios.
From this analysis, we derived two key insights that shaped our design:
Insight 1: Two Types of Failures
Failures fall into two distinct categories:
- Failures that happen before the
PRECOMMITphase succeeds, which always result in aROLLBACK. - Failures that happen after the
PRECOMMITphase succeeds, which always result in aCOMMIT.
The transition happens when all databases respond to the PREPARE TRANSACTION command from the transaction coordinator. We consider the responses to PREPARE TRANSACTION as votes from each database on the decision to commit. This to be a unanimous decision - if any database returns an error, we will force everyone to roll back with ROLLBACK PREPARED command. If every database responded successfully, we have a successful vote to commit, everyone is committed to commit the transaction. At this point, we say that the commit is "doomed to succeed", as per Postgres we can no longer return errors or roll back.
Insight 2: All database failures are communication failures
All types of database failures result in a database failing to respond to the transaction coordinator within a specified timeout. This is a classic result in distributed systems. The insight is that this failure to communicate leads to uncertainty about the state of the transaction. We don't know whether the faulty database prepare, rolled back or committed the transaction. Resolving this uncertainty requires restoring communication with the database and determining its state. Therefore, the first step in handling failures is reconciling the current state of the system.
Reconciling transaction states
To determine the state of transactions, we use information from several sources:
pg_prepared_xact: This is where Postgres stores the state of prepared transactions. Transactions in this table have been successfully prepared but not yet committed.distributed_transactions: This is a table that Nile maintains on each database. It is updated as part of every DDL transaction, but rows only become visible to other sessions after the transaction successfully commits. This visibility is enforced by PostgreSQL's ACID guarantees. Additionally, we maintain a centralized version of this table in a separate metadata database, which provides a fast, approximate view of transaction states. The localdistributed_transactionstable on each database is the authoritative source of truth, while the centralized table is maintained on a best-effort basis and may not always be completely up to date.dist_tx_participants: This table, located in the metadata database, tracks the state of each transaction for every participating database. Like the centralizeddistributed_transactionstable, it provides an optimized but not always current view. We use this table to improve efficiency but verify its data against individual databases for accuracy.- Transaction Coordinator in-memory state: The transaction coordinator maintains an in-memory cache of active database connections, transaction IDs, and their statuses. Unlike the other sources, this state is not persisted. If the coordinator crashes, its state is reconstructed using the other sources.
PostgreSQL's implementation of transactions and ACID guarantees ensures that all state information we need is safely persisted in the database. Its atomicity, isolation, and durability primitives form the backbone of our reliable architecture.
During failure recovery, we collect the state from all these sources and reconcile it into a consistent state using few simple rules. Lets look at how these rules play out in two scenarios - a failed database and a failed transaction coordinator.
Recovering from database failure
This scenario occurs the transaction coordinator loses contact with a database. The first priority is to re-establish communication. Unfortunately, Postgres does not provide "database is back up" hook that can be used for a callback. As a result, both the coordinator and the pg_karnak extension periodically check the connection and attempt to reconnect if there is an issue. Once a connection is re-established, the transaction coordinator will check pg_prepared_xact and distributed_transactions tables on the recovering database. For every open transaction in the coordinator's in-memory state, the recovering database can be in one of three states:
- Transaction committed successfuly: In this case, the coordinator updates its in-memory state and the status tables in the metadata database accordingly.
- Transaction prepared successfully but did not commit: Here, the coordinator checks the results of the transaction vote in its in-memory state, adding a "yes" vote from the recovered database. Based on the overall vote, the coordinator then decides if the transaction should commit or roll-back and distributes the appropriate commands.
- Transaction does not appear in either of the database state tables: This indicates that the database already rolled back the transaction, and never successfully prepared it. This means that the database voted "no" during the commit vote, and the transaction coordinator has to distribute
ROLLBACK PREPAREDto the other participating databases.
There is a special case for database failure, which is the case where the database where the transaction originated has failed. This database is responsible for notifying the transaction coordinator that about the XACT_EVENT_PRE_COMMIT and XACT_EVENT_COMMIT events for the transaction. If the originating database fails, the coordinator may be stuck with "orphaned" transactions that were never prepared or committed. To handle this, the coordinator relies on the transaction timeouts and a scheduled thread to roll back the orphaned transaction.
Recovering from coordinator failure
If the coordinator itself fails, the first priority is to reconstruct its in-memory state so it can resume managing ongoing transactions and complete them. The coordinator first uses the latest state from the status tables in the metadata database, then checks the state of individual databases. For each transaction, a database can have it in one of three states: committed, prepared or nonexistent. This leads to the following scenarios:
- Transaction is in a committed state in all databases: In this case, the coordinator will update the in-memory state and the status tables in the metadata database to reflect the committed status.
- Transaction is in prepared state in some databases and committed in others: This indicates that the commit vote was successful, but
COMMIT PREPAREDwasn't fully distributed. The coordinator will distributeCOMMIT PREPAREDto the databases still in prepared state and complete the transaction. - Transaction is in prepared state in some databases and nonexistent in others: This indicates a failed vote. Databases where the transaction does not exist have already rolled back the transaction. The coordinator will distribute
ROLLBACK PREPAREDto the remaining databases. - Transaction is in committed state in some databases and nonexistent in others: This should never ever happen. If some databases committed, it indicates a unanimous vote to commit, yet databases without the transaction voted "no" and rolled back. This inconsistency is theoretically impossible. After months of intensive testing and production use, we have never encountered this situation.
And that's it—our distributed DDL system can now handle any failure scenario. You might be curious about how we tested all of this, but that's a topic for another blog post.
Sum things up
We've taken a deep dive into the details of an architecture that, while not overly complex as far as distributed systems go, addresses some challenging problems. Let's recap the key points:
Nile re-engineered Postgres for multi-tenant applications with virtual tenant databases. Each virtual tenant database provides isolation and flexibility to independently place, store, back up or branch tenant's data. At the same time, we preserve the developer experience of working with a single database, allowing queries—including DDL—to span all tenant databases seamlessly.
To maintain the expected behavior of DDLs across all tenants and multiple physical databases, we developed a distributed transaction architecture. This architecture consists of a PostgreSQL extension, a transaction coordinator and a metadata store.
We demonstrated how our extension hooks into the DDL processing flow via processUtility_hook and hooks into the transaction lifecycle using XactCallback and its events. We also showed how the extension leverages low-level lock structures to implement the precise locking behavior required — functionality not exposed by higher-level PostgreSQL commands.
We discussed how the transaction coordinator initializes distributed transactions, distributes DDL commands, and relies on PostgreSQL's existing transaction mechanisms and guarantees to manage commits and recover from failures. By building on PostgreSQL's proven architecture—refined over 35 years of production use—we ensure robustness and reliability.
Finally, perhaps the most significant insight we gained is that while multi-tenant applications have been around for decades, their needs are only partially addressed by most existing databases. We see this as an opportunity to tackle interesting technical challenges specific to multi-tenancy. Reliably distributing DDLs is just one example of such a requirement. Nile focuses on solving these multi-tenant challenges systematically at the database level, addressing the issues every engineer encounters but few platforms tackle comprehensively. Sign up to Nile and join us on this journey.